Prerequisites
- Install IoT Bridge for Snowflake into your AWS account
- Before being able to access the
...
- Virtual Machine you must have completed the installation process here.
...
Summary
IoT Bridge for Snowflake (IBSNOW) is an application that connects to an MQTT Server (such as Chariot MQTT Server or AWS IoT Core) and consumes MQTT Sparkplug messages from Edge devices. These messages must be formatted as Sparkplug Templates. Sparkplug Templates are defined in the Sparkplug Specification. These Templates are used to create the data in Snowflake automatically with no additional coding or configuration. Then multiple instances of these Templates generate the Assets and start to populate with real time data sent on change only, thus significantly reducing the amount of data being sent to the cloud. For further details on Snowflake, refer to the documentation here. For further details on Eclipse Sparkplug, refer to the Eclipse Sparkplug resources.
This Quickstart document covers how IoT Bridge can be used to consume MQTT Sparkplug data and create and update data in Snowflake. This will show how to configure IoT Bridge as well as show how to use Inductive Automation's Ignition platform along with Cirrus Link's MQTT modules to publish device data to an MQTT Server. This data will ultimately be consumed by IoT Bridge to create and update the Snowflake components. This tutorial will use the AWS IoT Core MQTT Server implementation. However, IBSNOW does work with any MQTT v3.1.1 compliant MQTT Server including Cirrus Link's MQTT Servers.
It is also important to note that Ignition in conjunction with Cirrus Link's MQTT Transmission module converts Ignition User Defined Types (UDTs) to Sparkplug Templates. This is done automatically by the MQTT Transmission module. So, much of this document will refer to UDTs rather than Sparkplug Templates since that is what they are in Ignition. More information on Inductive Automation's Ignition platform can be found here. Additional information on Cirrus Link's MQTT Transmission module can be found here.
AWS Setup
Before configuring IoT Bridge (IBSNOW), you must register a 'thing' connection in AWS IoT Core. Begin by browsing to AWS IoT Core in your AWS account. Make sure you are in the same AWS region that you have already deployed IBSNOW to in the prerequisite step. Begin by expanding 'Secure' and click 'Policies' as shown below.
 Image Removed
Image Removed
Now click the 'Create a policy' button. This will bring up the following page.
 Image Removed
Image Removed
Set the following parameters for the policy.
...
- Some friendly name you will remember
...
Set to the following JSON document but replace the following
...
ACCOUNT_ID: Your AWS Account ID
| Code Block |
|---|
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iot:Connect",
"iot:Publish",
"iot:Subscribe",
"iot:Receive",
"iot:RetainPublish"
],
"Resource": "arn:aws:iot:AWS_REGION:ACCOUNT_ID:*"
}
]
} |
Example JSON document with region and account identifier set in the ARN:
| Code Block |
|---|
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iot:Connect",
"iot:Publish",
"iot:Subscribe",
"iot:Receive",
"iot:RetainPublish"
],
"Resource": "arn:aws:iot:us-west-2:123456789012:*"
}
]
} |
Finally click 'Create' in the lower right. This will show the newly created policy.
 Image Removed
Image Removed
At this point a 'thing' can be created. We'll use the policy a bit later in the procedure. To create the thing, expand 'Manage' on the left navigation panel and click 'All devices → Things' as shown below.
 Image Removed
Image Removed
Click 'Create things'. This will bring up the page below.
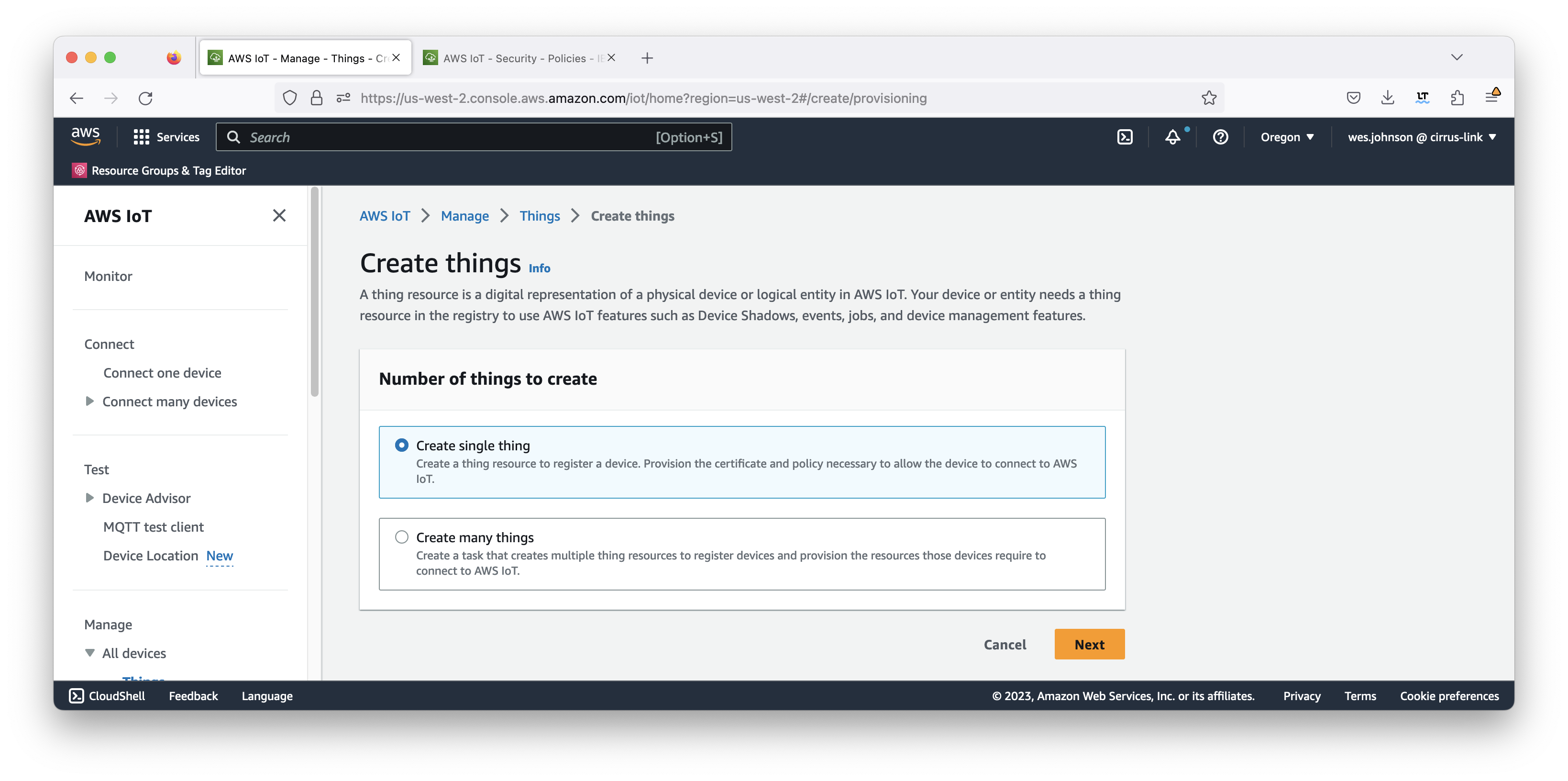 Image Removed
Image Removed
Now click 'Create a single thing'. This will open the following page. Give your thing a name (such as MyEdgeNode) and then click 'Next'.
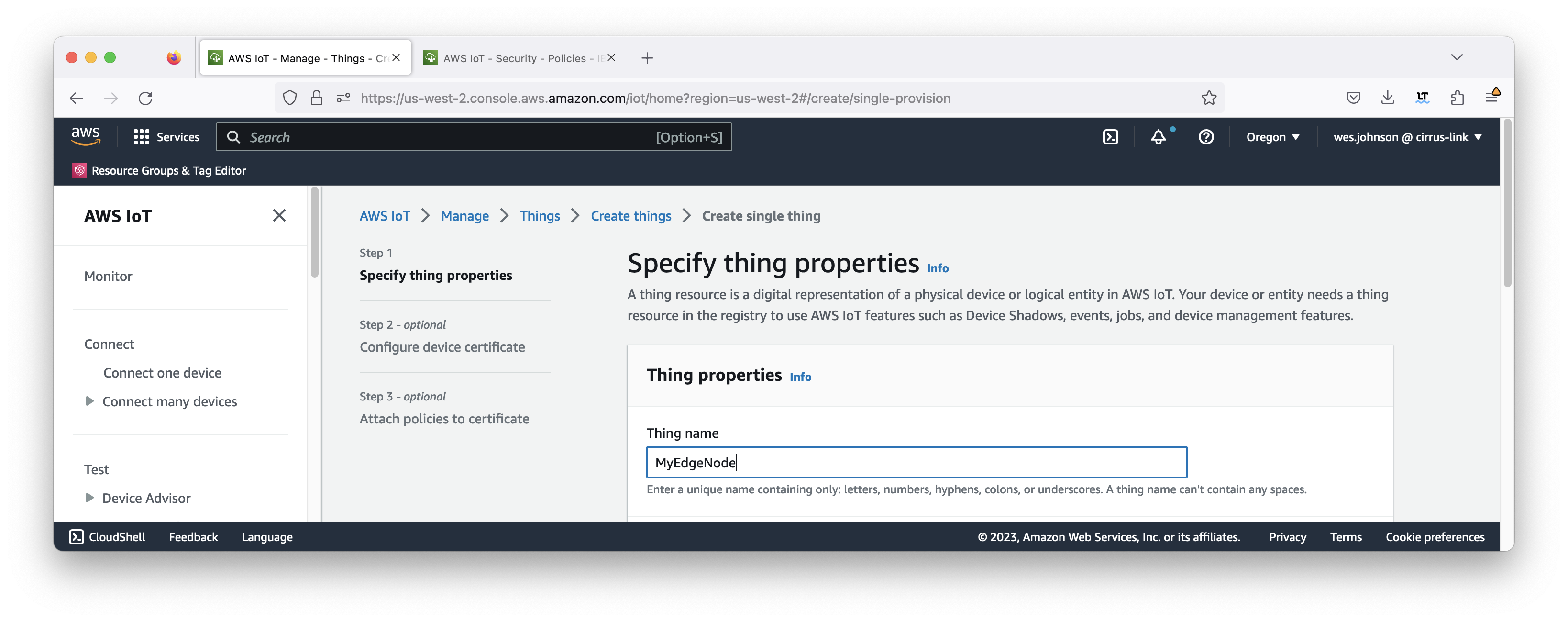 Image Removed
Image Removed
This will bring up the following page. Click the 'Auto-generate a new certificate (recommended)' option shown below.
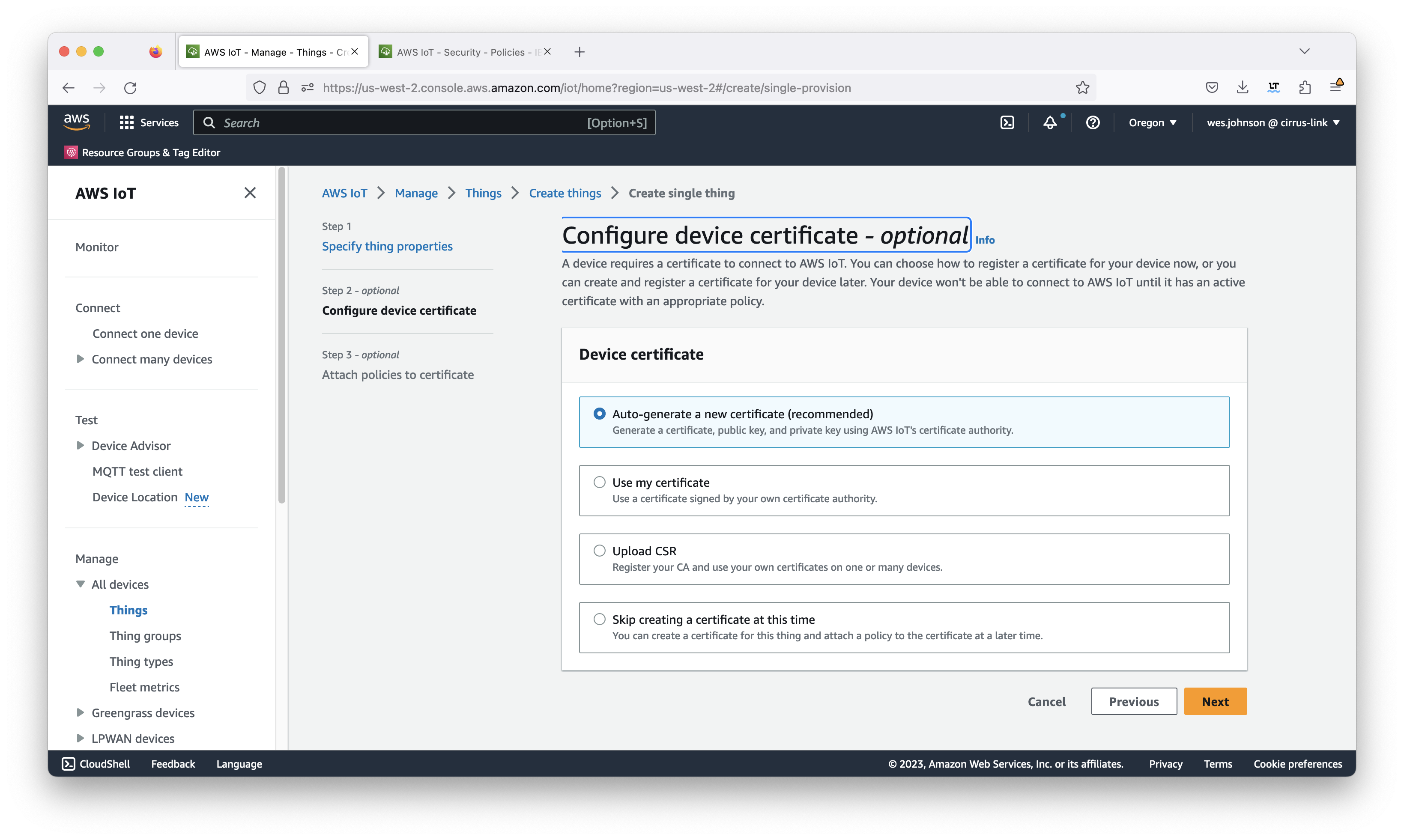 Image Removed
Image Removed
This will bring up the page similar to what is shown below. Select the policy that was created earlier in this tutorial also shown below and click 'Create thing'.
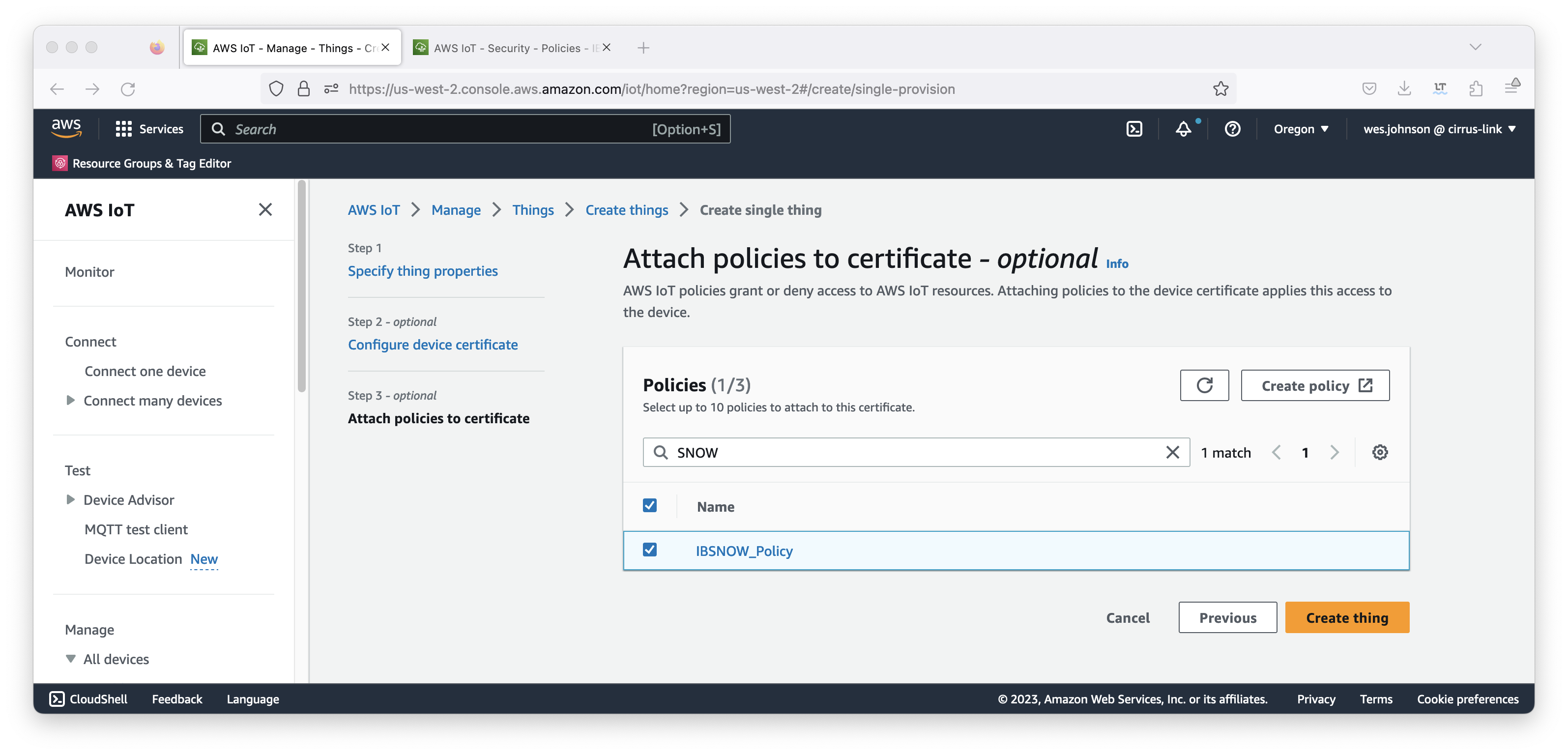 Image Removed
Image Removed
This will show the following download page.
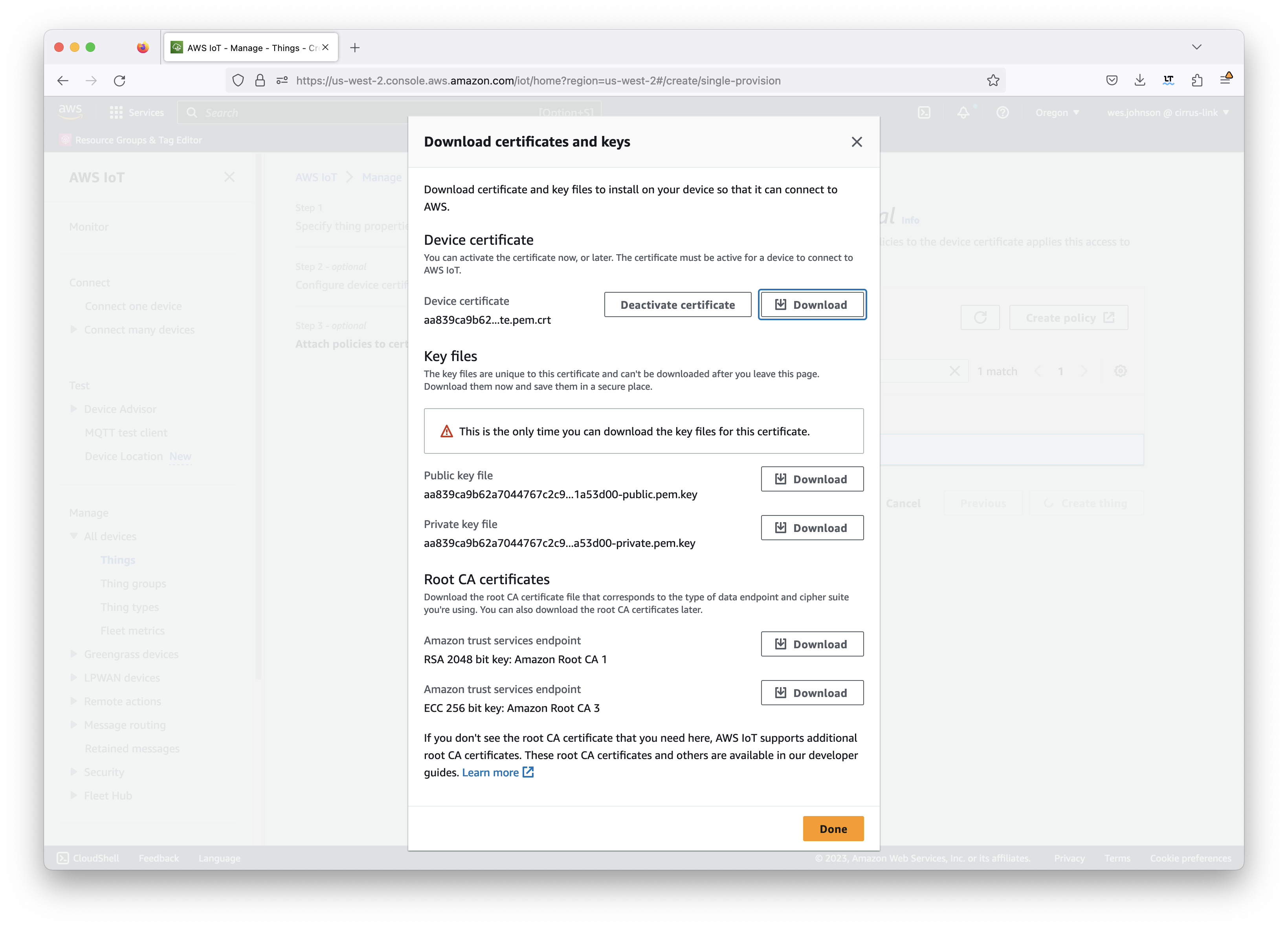 Image Removed
Image Removed
At this point, you must download the following files. Do not proceed until you have downloaded them as you will not get another chance.
- Device certificate
- This file ends in 'certificate.pem.crt'
- Public key file
- This file ends in 'public.pem.key'
- Private key file
- This file ends in 'private.pem.key'
- Root CA certificate
These will all be used in the IBSNOW configuration to connect to AWS IoT later. These files will not be accessible later and must be downloaded now. In addition, there is a link to download the root CA for AWS IoT. Make sure to download this as well. The 'RSA 2048 bit key: Amazon Root CA 1' is the preferred root certificate to download at the time of this writing.
At this point you should have three files where 'UUID' will be some UUID specific to your thing. Do not proceed until you have at least the following three files.
- UUID.certificate.pem.crt
- UUID.private.pem.key
- AmazonRootCA1.pem
Once you have these, click the 'Done' button. This will bring up the following page showing the new thing.
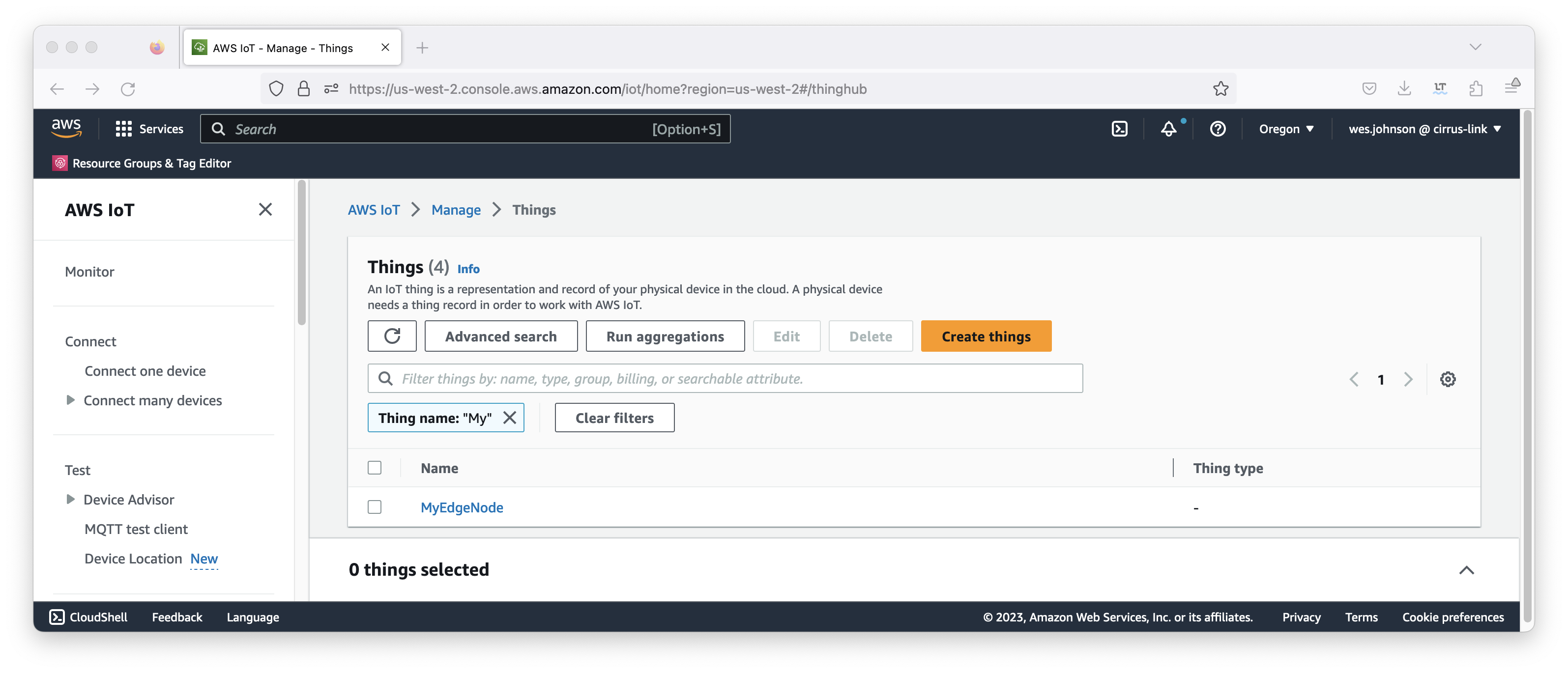 Image Removed
Image Removed
At this point, a thing has been defined with an associated certificate which also has a policy attached to it.
Now we need to get the AWS IoT Core Endpoint. Do so by selecting 'Settings' from the bottom section of the left navigation panel as shown below.
 Image Removed
Image Removed
When selected, your AWS IoT Endpoint will be displayed. Note it for future use when configuring IBSNOW.
Snowflake Setup
If you don't have a Snowflake account, open a Web Browser and go to https://www.snowflake.com. Follow the instructions there to start a free trial. After creating an account, log in to Snowflake via the Web Console. You should see something like what is shown below.
 Image Removed
Image Removed
Create a new 'SQL Worksheet' by clicking the blue + button in the upper right hand corner of the window as shown below.
 Image Removed
Image Removed
Copy and paste the following SQL script into the center pane. Click the 'Expand source' button on the right to copy the script source code
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 01 |
|---|
| collapse | true |
|---|
|
-- =========================
-- In this script, we are setting up assets related to the staging database
-- and associated assets. These are:
-- - Database
-- - Staging schema
-- The database & schema will be owned by SYSADMIN
-- REPLACE THE SESSION VARIABLE ACCORDING TO YOUR ENVIRONMENT
-- =========================
set cl_bridge_staging_db = 'CL_BRIDGE_STAGE_DB';
set staging_schema = 'stage_db';
-- >>>>>>>>>>>>>>>>>>>>>> DATABASE >>>>>>>>>>>>>>>>>>>>>>>>>
use role sysadmin;
create database if not exists identifier($cl_bridge_staging_db)
-- DATA_RETENTION_TIME_IN_DAYS = 90
-- MAX_DATA_EXTENSION_TIME_IN_DAYS = 90
comment = 'used for storing messages received from CirrusLink Bridge'
;
-- >>>>>>>>>>>>>>>>>>>>>> STAGING SCHEMA >>>>>>>>>>>>>>>>>>>>>>>>>
use database identifier($cl_bridge_staging_db);
create schema if not exists identifier($staging_schema)
with managed access
-- data_retention_time_in_days = 90
-- max_data_extension_time_in_days = 90
comment = 'Used for staging data direct from CirrusLink Bridge';
-- >>>>>>>>>>>>>>>>>>>>>> STAGING SCHEMA ASSETS >>>>>>>>>>>>>>>>>>>>>>>>>
use schema identifier($staging_schema);
-- =========================
-- Define tables
-- =========================
create or replace table sparkplug_raw (
msg_id varchar
,msg_topic varchar
,namespace varchar
,group_id varchar
,message_type varchar
,edge_node_id varchar
,device_id varchar
,msg variant
,inserted_at number
)
change_tracking = true
cluster by (message_type ,group_id ,edge_node_id ,device_id)
comment = 'Used for storing json messages from sparkplug bridge/gateway'
; |
After pasting the code into the center pane of the SQL Worksheet, click the drop down arrow next to the blue play button in the upper right corner of the window and click 'Run All' as shown below.
 Image Removed
Image Removed
After doing so, you should see a message in the 'Results' pane denoting the SPARKPLUG_RAW table was created successfully as shown below.
 Image Removed
Image Removed
Now, repeat the process for each of the following scripts in order. Each time, fully replace the contents of the SQL script with the new script and click the 'Run All' button after pasting each script. Make sure no errors are displayed in the Results window after running each script.
Script 02
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 02 |
|---|
| collapse | true |
|---|
|
-- =========================
-- In this script, we are setting up assets related to the node database
-- ,which would eventually contain all the device specific views and tables.
-- At the very core, the following assets are created:
-- - Node Database
-- - Staging schema
-- The database & schema will be owned by SYSADMIN
-- REPLACE THE SESSION VARIABLE ACCORDING TO YOUR ENVIRONMENT
-- =========================
set staged_sparkplug_raw_table = 'cl_bridge_stage_db.stage_db.sparkplug_raw';
set cl_bridge_node_db = 'cl_bridge_node_db';
set staging_schema = 'stage_db';
-- >>>>>>>>>>>>>>>>>>>>>> DATABASE >>>>>>>>>>>>>>>>>>>>>>>>>
use role sysadmin;
create database if not exists identifier($cl_bridge_node_db)
-- DATA_RETENTION_TIME_IN_DAYS = 90
-- MAX_DATA_EXTENSION_TIME_IN_DAYS = 90
comment = 'used for storing flattened messages processed from the staging database'
;
-- >>>>>>>>>>>>>>>>>>>>>> STAGING SCHEMA >>>>>>>>>>>>>>>>>>>>>>>>>
use database identifier($cl_bridge_node_db);
create schema if not exists identifier($staging_schema)
with managed access
-- data_retention_time_in_days = 90
-- max_data_extension_time_in_days = 90
comment = 'used for storing flattened messages processed from the staging database';
-- >>>>>>>>>>>>>>>>>>>>>> STAGING SCHEMA ASSETS >>>>>>>>>>>>>>>>>>>>>>>>>
use schema identifier($staging_schema);
-- =========================
-- Define tables
-- =========================
-- NOTE THE 'cl_bridge_stage_db.stage_db.sparkplug_raw' is hardcoded here; as the identifier
-- staged_sparkplug_raw_table replacement does not work.
create or replace view sparkplug_messages_vw
change_tracking = true
comment = 'parses out the core attributes from the message and topic.'
as
select
msg_id
,namespace
,group_id
,message_type
,edge_node_id
,device_id
,parse_json(msg) as message
,message:seq::int as message_sequence
,message:timestamp::number as message_timestamp
,inserted_at
from cl_bridge_stage_db.stage_db.sparkplug_raw
;
-- -- >>>>>>>>>>>>>>>>>>>>>>
create or replace view nbirth_vw
change_tracking = true
comment = 'filtered to nbirth messages. This is a mirror'
as
select
group_id ,edge_node_id
from sparkplug_messages_vw
where message_type = 'NBIRTH'
;
create or replace view node_machine_registry_vw
comment = 'Used to retreive the latest template definitions for a given group and edge_node'
as
with base as (
select
group_id ,edge_node_id
,max_by(message ,message_timestamp) as message
,max(message_timestamp) as latest_message_timestamp
from sparkplug_messages_vw
where message_type = 'NBIRTH'
group by group_id ,edge_node_id
)
select
group_id ,edge_node_id
,f.value as template_definition
,template_definition:name::varchar as machine
,template_definition:reference::varchar as reference
,template_definition:version::varchar as version
,template_definition:timestamp::int as timestamp
from base as b
,lateral flatten (input => b.message:metrics) f
where template_definition:dataType::varchar = 'Template'
;
-- -- >>>>>>>>>>>>>>>>>>>>>>
create or replace view node_birth_death_vw
comment = 'shows the latest node birth & death messages for each device'
as
select
b.* exclude(namespace)
,message_type as nbirth_or_ndeath_raw
,iff((message_type = 'NBIRTH') ,f.value:value ,null)::number as nbirth_bdSeq_raw
,iff((message_type = 'NDEATH') ,f.value:value ,null)::number as ndeath_bdSeq_raw
,inserted_at as nbirth_ndeath_inserted_at_raw
from sparkplug_messages_vw as b
,lateral flatten (input => b.message:metrics) as f
where message_type in ('NBIRTH' ,'NDEATH')
and f.value:name::varchar = 'bdSeq'
;
create or replace view device_records_vw
change_tracking = true
as
select
b.* exclude(namespace)
,null as nbirth_or_ndeath_raw
,null as nbirth_bdSeq_raw
,null as ndeath_bdSeq_raw
,null as nbirth_ndeath_inserted_at_raw
from sparkplug_messages_vw as b
where message_type in ('DBIRTH' ,'DDATA')
;
create or replace stream device_records_stream
on view device_records_vw
show_initial_rows = true
comment = 'used for monitoring latest device messages'
;
create or replace view sparkplug_msgs_nodebirth_contextualized_vw
as
with device_node_unioned as (
select *
from node_birth_death_vw
union all
select * exclude(METADATA$ROW_ID ,METADATA$ACTION ,METADATA$ISUPDATE)
from device_records_stream
)
select
-- group_id ,message_type ,edge_node_id ,device_id
-- ,message ,message_sequence ,inserted_at
* exclude(nbirth_or_ndeath_raw ,nbirth_bdSeq_raw ,ndeath_bdSeq_raw ,nbirth_ndeath_inserted_at_raw)
,nvl(nbirth_or_ndeath_raw
,lag(nbirth_or_ndeath_raw) ignore nulls over (order by inserted_at ,message_sequence)
) as nbirth_or_ndeath
,nvl(nbirth_bdSeq_raw
,lag(nbirth_bdSeq_raw) ignore nulls over (order by inserted_at ,message_sequence)
) as nbirth_bdSeq
,nvl(ndeath_bdSeq_raw
,lag(ndeath_bdSeq_raw) ignore nulls over (order by inserted_at ,message_sequence)
) as ndeath_bdSeq
,nvl(nbirth_ndeath_inserted_at_raw
,lag(nbirth_ndeath_inserted_at_raw) ignore nulls over (order by inserted_at ,message_sequence)
) as nbirth_ndeath_inserted_at
,case true
when (nbirth_or_ndeath = 'NBIRTH') then false
when ( (nbirth_or_ndeath = 'NDEATH') and (nbirth_bdSeq != ndeath_bdSeq) ) then false
when ( (nbirth_or_ndeath = 'NDEATH') and (nbirth_bdSeq = ndeath_bdSeq) ) then true
else true
end as is_last_known_good_reading
,case lower(message_type)
when lower('NBIRTH') then 1
when lower('DBIRTH') then 2
when lower('DDATA') then 3
when lower('DDEATH') then 4
when lower('NDEATH') then 5
else 99
end as message_type_order
,(nbirth_or_ndeath = 'NBIRTH') as is_node_alive
from device_node_unioned
;
create or replace view sparkplug_messages_flattened_vw
as
with base as (
select
-- sparkplugb message level
msg_id ,group_id, edge_node_id ,device_id ,message_type
,message_sequence ,inserted_at
,nbirth_or_ndeath ,nbirth_bdseq ,ndeath_bdseq
,nbirth_ndeath_inserted_at ,is_last_known_good_reading
,message_type_order ,is_node_alive
,message_timestamp as root_message_timestamp
-- attributes related to device data (ddata / dbirth)
,f.value:name::varchar as device_name
,f.value:value:reference::varchar as template_reference
,f.value:value:version::varchar as template_version
,f.value:timestamp::number as device_metric_timestamp
,f.value as ddata_msg
-- attributes related to device level metrics
,concat(msg_id ,'^' ,f.index ,'::',d.index) as device_measure_uuid
,d.value:name::varchar as measure_name
,d.value:value as measure_value
,d.value:timestamp::number as measure_timestamp
from sparkplug_msgs_nodebirth_contextualized_vw as b
,lateral flatten(input => b.message:metrics) as f
,lateral flatten(input => f.value:value:metrics) as d
where message_type in ('DBIRTH' ,'DDATA')
and template_reference is not null
)
select
group_id, edge_node_id ,device_id ,message_type
,message_sequence ,inserted_at
,nbirth_or_ndeath ,nbirth_bdseq ,ndeath_bdseq
,nbirth_ndeath_inserted_at ,is_last_known_good_reading
,message_type_order ,is_node_alive ,root_message_timestamp
,device_name ,template_reference ,template_version ,device_metric_timestamp ,ddata_msg
,null as is_historical
,device_measure_uuid
,object_agg(distinct measure_name ,measure_value) as measures_info
,measure_timestamp
,to_timestamp(measure_timestamp/1000) as measure_ts
,to_date(measure_ts) as measure_date
,hour(measure_ts) as measure_hour
from base
group by group_id, edge_node_id ,device_id ,message_type
,message_sequence ,inserted_at
,nbirth_or_ndeath ,nbirth_bdseq ,ndeath_bdseq
,nbirth_ndeath_inserted_at ,is_last_known_good_reading
,message_type_order ,is_node_alive ,root_message_timestamp
,device_name ,template_reference ,template_version ,device_metric_timestamp ,ddata_msg
,is_historical ,device_measure_uuid
,measure_timestamp
;
create or replace transient table sparkplug_device_messages (
group_id varchar
,edge_node_id varchar
,device_id varchar
,message_type varchar
,message_sequence number
,inserted_at number
,nbirth_or_ndeath varchar
,nbirth_bdseq number
,ndeath_bdseq number
,nbirth_ndeath_inserted_at number
,is_last_known_good_reading boolean
,message_type_order number
,is_node_alive boolean
,root_message_timestamp number
,device_name varchar
,template_reference varchar
,template_version varchar
,device_metric_timestamp number
,ddata_msg variant
,is_historical boolean
,device_measure_uuid varchar
,measures_info variant
,measure_timestamp number
,measure_ts timestamp
,measure_date date
,measure_hour number
)
cluster by ( group_id ,edge_node_id ,device_id
,template_reference ,template_version ,device_name
,measure_date ,measure_hour)
comment = 'materialized version of the sparkplug_messages_flattened_vw for easier downstream pipelines.'
;
-- -- >>>>>>>>>>>>>>>>>>>>>>
-- ================
-- NODE BIRTH related assets
-- ================
create or replace stream nbirth_stream
on view nbirth_vw
show_initial_rows = true
comment = 'stream to monitor for nbirth messages, so that assets are created automatically'
; |
- Expected Result: Stream NBIRTH_STREAM successfully created.
Script 03
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 03 |
|---|
| collapse | true |
|---|
|
set cl_bridge_node_db = 'cl_bridge_node_db';
set staging_schema = 'stage_db';
use role sysadmin;
use database identifier($cl_bridge_node_db);
use schema identifier($staging_schema);
CREATE OR REPLACE PROCEDURE synch_device_messages()
RETURNS VARIANT NOT NULL
LANGUAGE JAVASCRIPT
COMMENT = 'Synch latest device updates and stores in table'
AS
$$
// --- MAIN --------------------------------------
var failure_err_msg = [];
var return_result_as_json = {};
var sucess_count = 0;
var failure_count = 0;
const qry = `
insert into sparkplug_device_messages
select *
from sparkplug_messages_flattened_vw
;`
res = [];
try {
var rs = snowflake.execute({ sqlText: qry });
sucess_count = sucess_count + 1;
} catch (err) {
failure_count = failure_count + 1;
failure_err_msg.push(` {
sqlstatement : ‘${qry}’,
error_code : ‘${err.code}’,
error_state : ‘${err.state}’,
error_message : ‘${err.message}’,
stack_trace : ‘${err.stackTraceTxt}’
} `);
}
return_result_as_json['asset_creation'] = res;
return_result_as_json['Success'] = sucess_count;
return_result_as_json['Failures'] = failure_count;
return_result_as_json['Failure_error'] = failure_err_msg;
return return_result_as_json;
$$;
CREATE OR REPLACE FUNCTION GENERATE_TEMPLATE_ASSET_BASE_NAME
(PARAM_TEMPLATE_NAME varchar ,PARAM_TEMPLATE_VERSION varchar)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for generating device template name.'
AS $$
function normalize_name_str(p_str) {
return p_str.replace(/[\W_]+/g,"_").trim().toLowerCase();
}
function get_device_view_base_name(p_machine ,p_version) {
const v = (p_version != null) ? p_version : "";
return normalize_name_str(`${p_machine}${v}`);
}
return get_device_view_base_name(PARAM_TEMPLATE_NAME ,PARAM_TEMPLATE_VERSION);
$$
;
CREATE OR REPLACE FUNCTION GENERATE_DEVICE_BASE_VIEW_DDL
( PARAM_GROUP_ID VARCHAR ,PARAM_EDGE_NODE_ID VARCHAR ,PARAM_TEMPLATE_REFERENCE VARCHAR
,PARAM_SOURCE_DB varchar
,PARAM_SOURCE_SCHEMA varchar
,PARAM_TARGET_SCHEMA VARCHAR
,PARAM_TEMPLATE_ASSET_BASE_NAME varchar
,PARAM_TEMPLATE_DEFN variant
,PARAM_FORCE_RECREATE boolean
)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for generating generic view ddl for device template.'
AS $$
var stmt_condition = `create view if not exists`;
if (PARAM_FORCE_RECREATE == true)
stmt_condition = `create or replace view`;
const sql_stmt = `
${stmt_condition} ${PARAM_SOURCE_DB}.${PARAM_TARGET_SCHEMA}.${PARAM_TEMPLATE_ASSET_BASE_NAME}
as
select
group_id ,edge_node_id ,device_id ,message_type ,message_sequence ,root_message_timestamp
,inserted_at ,nbirth_or_ndeath ,nbirth_bdseq ,ndeath_bdseq
,nbirth_ndeath_inserted_at ,is_last_known_good_reading
,message_type_order ,is_node_alive
,device_name ,template_version ,device_metric_timestamp ,ddata_msg ,is_historical
,device_measure_uuid ,measures_info ,measure_timestamp
,measure_ts ,measure_date ,measure_hour
from ${PARAM_SOURCE_SCHEMA}.sparkplug_device_messages
where group_id = '${PARAM_GROUP_ID}'
and edge_node_id = '${PARAM_EDGE_NODE_ID}'
and template_reference = '${PARAM_TEMPLATE_REFERENCE}'
;
`;
return sql_stmt;
$$
;
CREATE OR REPLACE FUNCTION GENERATE_DEVICE_VIEW_DDL
( PARAM_GROUP_ID VARCHAR ,PARAM_EDGE_NODE_ID VARCHAR ,PARAM_TEMPLATE_REFERENCE VARCHAR
,PARAM_SOURCE_DB varchar
,PARAM_TARGET_SCHEMA VARCHAR
,PARAM_TEMPLATE_ASSET_BASE_NAME varchar
,PARAM_TEMPLATE_DEFN variant
,PARAM_FORCE_RECREATE boolean
)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for generating generic view ddl for device template.'
AS $$
function normalize_name_str(p_str) {
return p_str.replace(/[\W_]+/g,"_").trim().toLowerCase();
}
function build_column_ddl_defn(p_template_defn) {
var cols = [];
const data_type_map = {
"Int32":"::integer"
,"Int64":"::integer"
,"Float":"::double"
,"Template":"::variant"
,"Boolean":"::boolean"
,"String":"::varchar"
};
const m_entries = p_template_defn['value']['metrics']
for (const [m_key, m_value] of Object.entries(m_entries)) {
const measure_name = m_value['name'];
const dtype = m_value['dataType'];
const mname_cleansed = normalize_name_str(measure_name);
// # default string cast, if the datatype is not mapped
const dtype_converted = data_type_map[dtype] || "::varchar";
const col_defn = `measures_info:"${measure_name}"${dtype_converted} as ${mname_cleansed} `;
cols.push(col_defn);
}
const cols_joined = cols.join(',');
return cols_joined
}
const vw_name = `${PARAM_TEMPLATE_ASSET_BASE_NAME}_vw`;
const cols_joined = build_column_ddl_defn(PARAM_TEMPLATE_DEFN)
const sql_stmt = `
create or replace view ${PARAM_SOURCE_DB}.${PARAM_TARGET_SCHEMA}.${vw_name}
as
select
* exclude(ddata_msg ,measures_info ,template_version)
,${cols_joined}
from ${PARAM_SOURCE_DB}.${PARAM_TARGET_SCHEMA}.${PARAM_TEMPLATE_ASSET_BASE_NAME}
;
`;
return sql_stmt;
$$;
CREATE OR REPLACE FUNCTION GENERATE_DEVICE_ASOF_VIEW_DDL
( PARAM_GROUP_ID VARCHAR ,PARAM_EDGE_NODE_ID VARCHAR ,PARAM_TEMPLATE_REFERENCE VARCHAR
,PARAM_SOURCE_DB varchar
,PARAM_TARGET_SCHEMA VARCHAR
,PARAM_TEMPLATE_ASSET_BASE_NAME varchar
,PARAM_TEMPLATE_DEFN variant
,PARAM_FORCE_RECREATE boolean
)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for generating device asof view ddl.'
AS $$
function normalize_name_str(p_str) {
return p_str.replace(/[\W_]+/g,"_").trim().toLowerCase();
}
function build_column_ddl_defn(p_template_defn) {
var cols = []
const data_type_map = {
"Int32":"::integer"
,"Int64":"::integer"
,"Float":"::double"
,"Template":"::variant"
,"Boolean":"::boolean"
,"String":"::varchar"
}
const m_entries = p_template_defn['value']['metrics']
for (const [m_key, m_value] of Object.entries(m_entries)) {
const measure_name = m_value['name'];
const dtype = m_value['dataType'];
const mname_cleansed = normalize_name_str(measure_name);
// # default string cast, if the datatype is not mapped
const dtype_converted = data_type_map[dtype] || "::varchar";
const col_defn = `nvl(${mname_cleansed}
,lag(${mname_cleansed}) ignore nulls over (order by message_type_order ,measure_timestamp ,message_sequence)
) AS ${mname_cleansed}
`;
cols.push(col_defn);
}
const cols_joined = cols.join(',');
return cols_joined
}
const vw_name = `${PARAM_TEMPLATE_ASSET_BASE_NAME}_vw`;
const recordasof_vw_name = `${PARAM_TEMPLATE_ASSET_BASE_NAME}_asof_vw`;
const cols_joined = build_column_ddl_defn(PARAM_TEMPLATE_DEFN)
const sql_stmt = `
create or replace secure view ${PARAM_SOURCE_DB}.${PARAM_TARGET_SCHEMA}.${recordasof_vw_name}
as
select
group_id ,edge_node_id ,device_id ,device_name ,message_sequence
,root_message_timestamp ,inserted_at
,message_type ,message_type_order
,nbirth_or_ndeath ,nbirth_bdseq ,ndeath_bdseq
,nbirth_ndeath_inserted_at ,is_last_known_good_reading
,is_node_alive
,is_historical
,device_measure_uuid
,measure_timestamp
,measure_ts ,measure_date ,measure_hour
,${cols_joined}
from ${PARAM_SOURCE_DB}.${PARAM_TARGET_SCHEMA}.${vw_name}
order by measure_timestamp ,message_type_order ,message_sequence
;
`;
return sql_stmt;
$$;
|
- Expected Result: Function GENERATE_DEVICE_ASOF_VIEW_DDL successfully created.
Install an MQTT Server configured with a real signed TLS certificate
| Tip |
|---|
This quickstart guide uses the Chariot MQTT Server can be installed as a free trial from the AWS Marketplace. Review the Chariot MQTT Server Configuration for details on how to upload the necessary certificates and keys for enabling SSL/TLS |
| Note |
|---|
If you choose not to use Chariot MQTT Server, any Sparkplug compliant MQTT Server will work. | Warning |
|---|
| AWS IoT Core has a message size limit of 128KB and will disconnect the client if it receives a message that exceeds this limit. If you have a large number of UDT definitions/instances and/or have very large UDTs, you will very likely hit this limit when sending your UDTs to AWS IoT Core. Review this document for ways to reduce the message size. |
|
Summary
IoT Bridge for Snowflake (IBSNOW) is an application that connects to an MQTT Server (such as Chariot MQTT Server or AWS IoT Core) and consumes MQTT Sparkplug messages from Edge devices.
When these messages are formatted as Sparkplug Templates, as defined in the Sparkplug Specification, the templates are used to create the data in Snowflake automatically with no additional coding or configuration.
| Warning |
|---|
| If the messages do not use templates, they will be stored in a database table as unprocessed messages and additional work will be required to use this data in Snowflake. |
Then multiple instances of these Templates generate the Assets and start to populate with real time data sent on change only, thus significantly reducing the amount of data being sent to the cloud. For further details on Snowflake, refer to the documentation here. For further details on Eclipse Sparkplug, refer to the Eclipse Sparkplug resources.
This Quickstart document covers how IoT Bridge can be used to consume MQTT Sparkplug data and create and update data in Snowflake. This will show how to configure IoT Bridge as well as show how to use Inductive Automation's Ignition platform along with Cirrus Link's MQTT modules to publish device data to an MQTT Server. This data will ultimately be consumed by IoT Bridge to create and update the Snowflake components. This tutorial will use the AWS IoT Core MQTT Server implementation. However, IBSNOW does work with any MQTT v3.1.1 compliant MQTT Server including Cirrus Link's MQTT Servers.
It is also important to note that Ignition in conjunction with Cirrus Link's MQTT Transmission module converts Ignition User Defined Types (UDTs) to Sparkplug Templates. This is done automatically by the MQTT Transmission module. So, much of this document will refer to UDTs rather than Sparkplug Templates since that is what they are in Ignition. More information on Inductive Automation's Ignition platform can be found here. Additional information on Cirrus Link's MQTT Transmission module can be found here.
Snowflake Setup
If you don't have a Snowflake account, open a Web Browser and go to https://www.snowflake.com. Follow the instructions there to start a free trial. After creating an account, log in to Snowflake via the Web Console. You should see something like what is shown below.
Image Added
Create a new 'SQL Worksheet' by clicking the blue + button in the upper right hand corner of the window as shown below.
Image Added
Copy and paste SQL Script 01 from Snowflake Setup Scripts into the center pane of the SQL Worksheet, click the drop down arrow next to the blue play button in the upper right corner of the window and click 'Run All' as shown below.
Image Added
After doing so, you should see a message in the 'Results' pane denoting the SPARKPLUG_RAW table was created successfully as shown below.
Image Added
Now, repeat the process for each of the following scripts in the Snowflake Setup Scripts in order. Each time, fully replace the contents of the SQL script with the new script and click the 'Run All' button after pasting each script. Make sure no errors are displayed in the Results window after running each script.
SQL Script 02 Expected Result: Stream NBIRTH_STREAM successfully created.
SQL Script 03 Expected Result: Function GENERATE_DEVICE_ASOF_VIEW_DDL successfully created.
SQL Script 04 Expected Result: Function CREATE_EDGE_NODE_SCHEMA successfully created.
SQL Script 05 Expected Result: Function CREATE_ALL_EDGE_NODE_SCHEMAS successfully created.
SQL Script 06 Expected Result: Statement executed successfully.
SQL Script 07 Expected Result: Statement executed successfully.
SQL Script 08 Expected Result: Statement executed successfully.
After all of the scripts have successfully executed, create a new user in Snowflake. This user will be used by IoT Bridge for Snowflake to push data into Snowflake. In the Snowflake Web UI, go to Admin → Users & Roles and then click '+ User' in the upper right hand corner. Give it a username of your choice and a secure password as shown below. For this example we're calling the user IBSNOW_INGEST so we know this user is for ingest purposes. See below for an example and then click 'Create User'.
| Warning |
|---|
| Force user to change password on first time login must be set to False. |
 Image Added
Image Added
In addition, the user must have a specific role to be able to stream data into Snowflake. Click the newly created user to see the following.
 Image Added
Image Added
In the bottom of the center 'Granted Roles' pane you will see this user has no roles. Click 'Grant Role' to set up a new role. Then, select the 'CL_BRIDGE_PROCESS_RL' role and click 'Grant' as shown below.
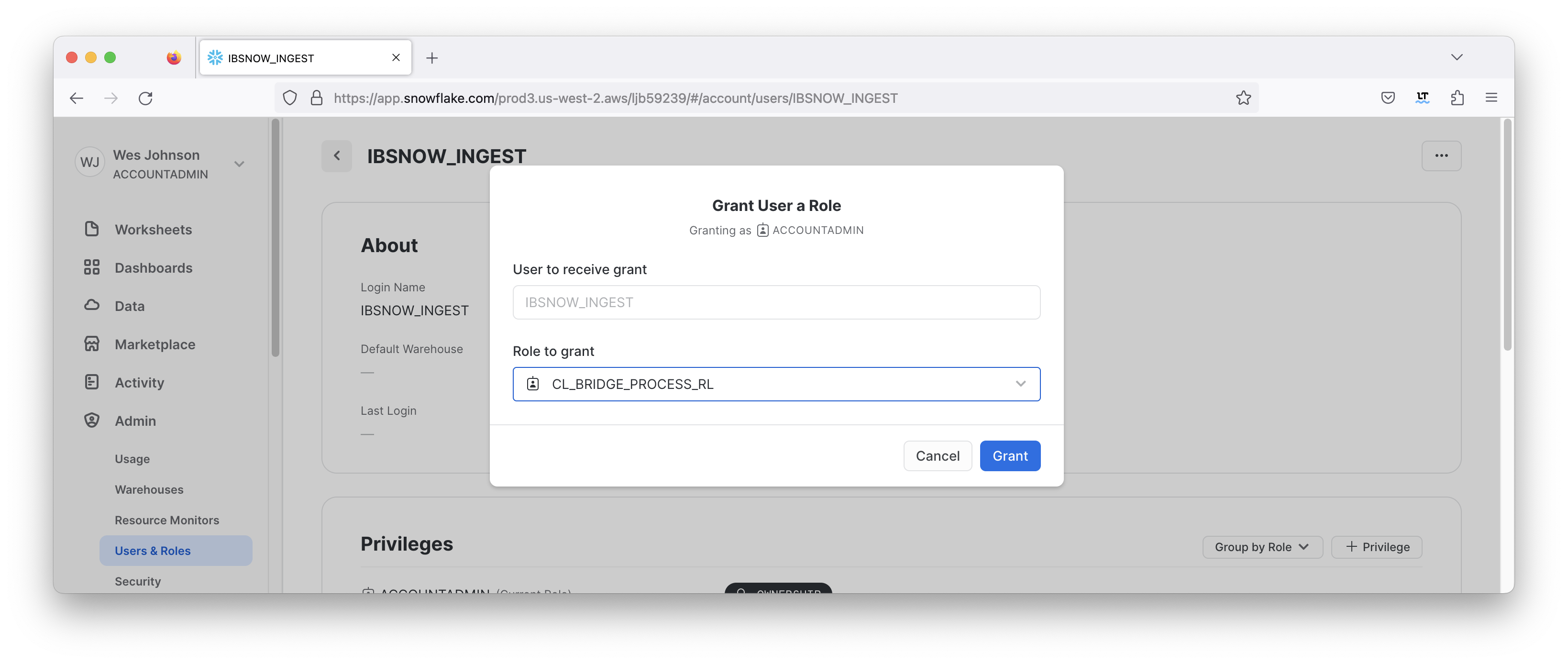 Image Added
Image Added
After this has been done successfully you will see the role now associated with the new user as shown below.
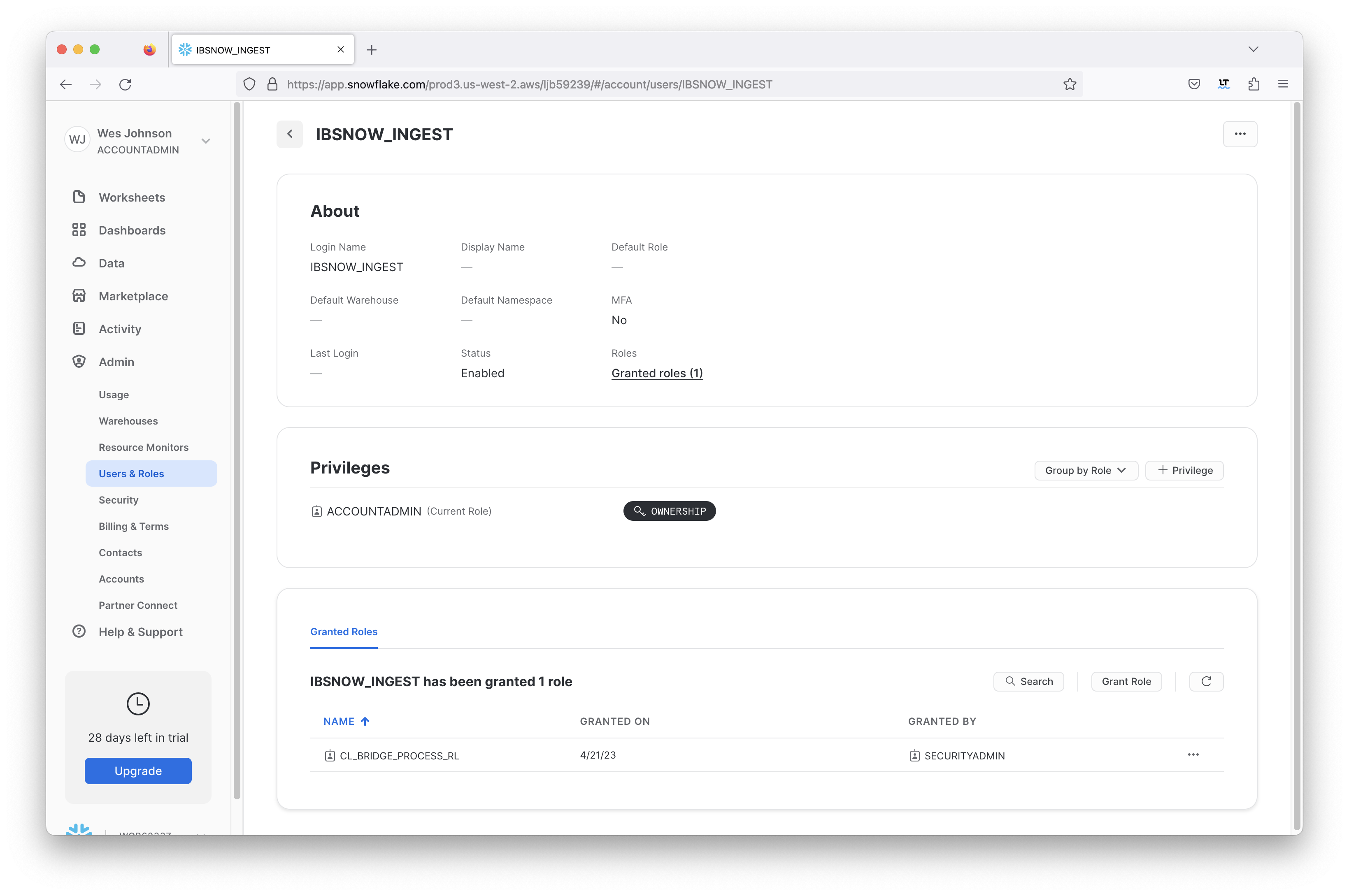 Image Added
Image Added
Now an unencrypted key pair must be generated and uploaded to Snowflake. This will be used for authentication by the IoT Bridge for Snowflake application to push data to Snowflake via the Snowflake Streaming API.
Attach the generated unencrypted public key to the IBSNOW_INGEST user that we just created for Snowflake ingest purposes.
| Tip |
|---|
See this document for details on how to generate this unencrypted key and assign this to a user in your snowflake account: https://docs.snowflake.com/en/user-guide/key-pair-auth. Note: The step "Configuring the Snowflake Client to User Key Pair Authentication" in the linked tutorial can be skipped. | Warning |
|---|
| The generated key MUST NOT be encrypted |
|
IoT Bridge Setup
First you will need access to the Snowflake IoT Bridge EC2 instance via SSH. See this document for information on how to do this.
Configuring the Snowflake properties
Now, modify the file /opt/ibsnow/conf/ibsnow.properties file. Set the following:
- mqtt_server_url
- mqtt_server_name
- Give it a meaningful name if desired
- mqtt_username
- The username for the MQTT connection if required
- If using Chariot MQTT Server, the default username is 'admin'
- mqtt_password
- The password for the MQTT connection if required
- If using Chariot MQTT Server, the default password is 'changeme'
- primary_host_id
- Set it to a text string such as 'IamHost'
- snowflake_streaming_client_name
- Some text string such as 'MY_CLIENT'
- snowflake_streaming_table_name
- This is the staged_sparkplug_raw_table created by the Snowflake setup in SQL Script 02
- If the default Snowflake setup scripts were used, this is 'SPARKPLUG_RAW'
- snowflake_notify_db_name
- snowflake_notify_schema_name
- snowflake_notify_warehouse_name
- This is the cl_bridge_ingest_wh created by the Snowflake setup in SQL Script 07
- If the default Snowflake setup scripts were used, this is 'cl_bridge_ingest_wh'
When complete, it should look similar to what is shown below.
| Note |
|---|
If you are using self-signed certificates rather than a real signed certificate, you will need to copy the CA certificate chain file uploaded to your MQTT Server to the bridge instance and set - mqtt_ca_cert_chain_path.1
- This is the filepath to the TLS Certificate Authority certificate chain
|
| Excerpt Include |
|---|
| IBSNOW: Snowflake IoT Bridge properties configuration |
|---|
| IBSNOW: Snowflake IoT Bridge properties configuration |
|---|
| nopanel | true |
|---|
|
Configuring the Snowflake streaming profile
Now modify the file /opt/ibsnow/conf/snowflake_streaming_profile.json as described in Setting snowflake_streaming_profile configuration
When complete, it should look similar to what is shown below.
| Excerpt Include |
|---|
| IBSNOW: Setting snowflake_streaming_profile configuration |
|---|
| IBSNOW: Setting snowflake_streaming_profile configuration |
|---|
| nopanel | true |
|---|
|
Now the service can be restarted to pick up the new configuration. Do so by running the following command.
sudo systemctl restart ibsnow |
At this point, IBSNOW should connect to AWS IoT Core and be ready to receive MQTT Sparkplug messages. Verify by running the following command.
tail -f /opt/ibsnow/log/wrapper.log
|
After doing so, you should see something similar to what is shown below. Note the last line is 'MQTT Client connected to ...'. That denotes we have successfully configured IBSNOW and properly provisioned AWS IoT Core.
| Code Block |
|---|
|
INFO|7263/0||23-06-29 20:19:32|20:19:32.932 [Thread-2 |
Script 04
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 04 |
|---|
| collapse | true |
|---|
|
set cl_bridge_node_db = 'cl_bridge_node_db';
set staging_schema = 'stage_db';
use role sysadmin;
use database identifier($cl_bridge_node_db);
use schema identifier($staging_schema);
CREATE OR REPLACE FUNCTION NORMALIZE_ASSET_NAME(P_STR VARCHAR)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for creating asset names without spaces/special characters.'
AS $$
return P_STR.replace(/[\W_]+/g,"_").trim().toLowerCase();
$$
;
CREATE OR REPLACE FUNCTION EDGENODE_SCHEMA_NAME(PARAM_SCHEMA_PREFIX VARCHAR ,PARAM_GROUP_ID VARCHAR ,PARAM_EDGE_NODE_ID VARCHAR)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for creating asset names for edgenode schema.'
AS $$
function normalize_name_str(p_str) {
return p_str.replace(/[\W_]+/g,"_").trim().toLowerCase();
}
const schema_name = `${PARAM_SCHEMA_PREFIX}_${PARAM_GROUP_ID}_${PARAM_EDGE_NODE_ID}`;
return normalize_name_str(schema_name);
$$
;
CREATE OR REPLACE FUNCTION GENERATE_EDGENODE_SCHEMA_DDL
(PARAM_SCHEMA_PREFIX VARCHAR ,PARAM_GROUP_ID VARCHAR
,PARAM_EDGE_NODE_ID VARCHAR ,PARAM_FORCE_RECREATE boolean)
RETURNS VARCHAR
LANGUAGE JAVASCRIPT
COMMENT = 'Used for generating edgenode schema ddl.'
AS $$
function normalize_name_str(p_str) {
return p_str.replace(/[\W_]+/g,"_").trim().toLowerCase();
}
// Returns the normalized schema name for the edgenode
function get_edgenode_schema_name(p_schema_prefix ,p_group_id ,p_edge_node_id) {
const schema_name = `${p_schema_prefix}_${p_group_id}_${p_edge_node_id}`;
return normalize_name_str(schema_name);
}
const schema_name = get_edgenode_schema_name(PARAM_SCHEMA_PREFIX ,PARAM_GROUP_ID ,PARAM_EDGE_NODE_ID);
var sql_stmt = `create schema if not exists ${schema_name}; `
if(PARAM_FORCE_RECREATE == true) {
sql_stmt = `create or replace schema ${schema_name}; `
}
return sql_stmt;
$$
;
CREATE OR REPLACE PROCEDURE create_edge_node_schema(PARAM_SCHEMA_PREFIX VARCHAR ,PARAM_GROUP_ID VARCHAR ,PARAM_EDGE_NODE_ID VARCHAR ,PARAM_FORCE_RECREATE boolean)
RETURNS VARIANT NOT NULL
LANGUAGE JAVASCRIPT
COMMENT = 'Creates edge node specific schema, supposed to be invoked as part of NBIRTH messsage'
AS
$$
function get_sql_stmt(p_schema_prefix ,p_group_id ,p_edge_node_id ,p_force_recreate) {
const sql_stmt = `select
'${p_schema_prefix}' as schema_prefix
,iff(${p_force_recreate} = 1 ,true ,false) as force_recreate
,edgenode_schema_name(schema_prefix ,group_id ,edge_node_id) as edgenode_schema_name
,generate_edgenode_schema_ddl(schema_prefix, group_id ,edge_node_id ,force_recreate) as edgenode_schema_ddl
,machine
,generate_template_asset_base_name(machine ,version) as machine_table_base_name
,template_definition
,generate_device_base_view_ddl
(group_id ,edge_node_id ,machine
,current_database() ,current_schema() ,edgenode_schema_name
,machine_table_base_name ,template_definition
,force_recreate) as device_base_view_ddl
,generate_device_view_ddl
(group_id ,edge_node_id ,machine
,current_database() ,edgenode_schema_name
,machine_table_base_name ,template_definition
,force_recreate) as device_view_ddl
,generate_device_asof_view_ddl
(group_id ,edge_node_id ,machine
,current_database() ,edgenode_schema_name
,machine_table_base_name ,template_definition
,force_recreate) as device_asof_view_ddl
from node_machine_registry_vw
where group_id = '${p_group_id}'
and edge_node_id = '${p_edge_node_id}'
;`
return sql_stmt;
}
// --- MAIN --------------------------------------
var failure_err_msg = [];
var return_result_as_json = {};
var sucess_count = 0;
var failure_count = 0;
const qry = get_sql_stmt(PARAM_SCHEMA_PREFIX ,PARAM_GROUP_ID ,PARAM_EDGE_NODE_ID ,PARAM_FORCE_RECREATE);
var sql_stmt = qry;
var schema_created = false;
res = [];
try {
var rs = snowflake.execute({ sqlText: qry });
while (rs.next()) {
machine = rs.getColumnValue('MACHINE');
edgenode_schema_name = rs.getColumnValue('EDGENODE_SCHEMA_NAME');
edgenode_schema_ddl = rs.getColumnValue('EDGENODE_SCHEMA_DDL');
device_base_view_ddl = rs.getColumnValue('DEVICE_BASE_VIEW_DDL');
device_view_ddl = rs.getColumnValue('DEVICE_VIEW_DDL');
device_asof_view_ddl = rs.getColumnValue('DEVICE_ASOF_VIEW_DDL');
if(schema_created == false) {
sql_stmt = edgenode_schema_ddl;
snowflake.execute({ sqlText: edgenode_schema_ddl });
//blind setting is not good,
//TODO check if the schema is indeed created
schema_created = true;
}
sql_stmt = device_base_view_ddl;
snowflake.execute({ sqlText: device_base_view_ddl });
sql_stmt = device_view_ddl;
snowflake.execute({ sqlText: device_view_ddl });
sql_stmt = device_asof_view_ddl;
snowflake.execute({ sqlText: device_asof_view_ddl });
sucess_count = sucess_count + 1;
res.push(edgenode_schema_name + '.' + machine);
}
} catch (err) {
failure_count = failure_count + 1;
failure_err_msg.push(` {
sqlstatement : ‘${sql_stmt}’,
error_code : ‘${err.code}’,
error_state : ‘${err.state}’,
error_message : ‘${err.message}’,
stack_trace : ‘${err.stackTraceTxt}’
} `);
}
return_result_as_json['asset_creation'] = res;
return_result_as_json['Success'] = sucess_count;
return_result_as_json['Failures'] = failure_count;
return_result_as_json['Failure_error'] = failure_err_msg;
return return_result_as_json;
$$;
|
- Expected Result: Function CREATE_EDGE_NODE_SCHEMA successfully created.
Script 05
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 05 |
|---|
| collapse | true |
|---|
|
set cl_bridge_node_db = 'cl_bridge_node_db';
set staging_schema = 'stage_db';
use role sysadmin;
use database identifier($cl_bridge_node_db);
use schema identifier($staging_schema);
CREATE OR REPLACE PROCEDURE create_all_edge_node_schemas(PARAM_SCHEMA_PREFIX VARCHAR ,PARAM_FORCE_RECREATE boolean)
RETURNS VARIANT NOT NULL
LANGUAGE JAVASCRIPT
COMMENT = 'Creates edge node specific schemas, supposed to be invoked as part of NBIRTH messsage'
AS
$$
// --- MAIN --------------------------------------
var failure_err_msg = [];
var return_result_as_json = {};
var sucess_count = 0;
var failure_count = 0;
const qry = `
select distinct group_id ,edge_node_id
,current_schema() as current_schema
from node_machine_registry_vw
where edge_node_id is not null
;`
//node_machine_registry_vw
//nbirth_stream
var current_schema = 'stage_db';
res = [];
try {
var rs = snowflake.execute({ sqlText: qry });
while (rs.next()) {
group_id = rs.getColumnValue('GROUP_ID');
edge_node_id = rs.getColumnValue('EDGE_NODE_ID');
current_schema = rs.getColumnValue('CURRENT_SCHEMA');
var schema_out = {}
schema_out['execution'] = snowflake.execute({
sqlText: `call create_edge_node_schema('${PARAM_SCHEMA_PREFIX}' ,'${group_id}' ,'${edge_node_id}' ,${PARAM_FORCE_RECREATE});`
});
res.push(schema_out);
}
sucess_count = sucess_count + 1;
} catch (err) {
failure_count = failure_count + 1;
failure_err_msg.push(` {
sqlstatement : ‘${qry}’,
error_code : ‘${err.code}’,
error_state : ‘${err.state}’,
error_message : ‘${err.message}’,
stack_trace : ‘${err.stackTraceTxt}’
} `);
}
return_result_as_json['asset_creation'] = res;
return_result_as_json['Success'] = sucess_count;
return_result_as_json['Failures'] = failure_count;
return_result_as_json['Failure_error'] = failure_err_msg;
return return_result_as_json;
$$;
|
- Expected Result: Function CREATE_ALL_EDGE_NODE_SCHEMAS successfully created.
Script 10
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 10 |
|---|
| collapse | true |
|---|
|
-- =========================
-- In this script, we are setting up roles specifically requiring help of
-- privlilleged roles like SYSADMIN. These are:
-- - Create a custom role
-- - Assign the custom role to create task and execute task
-- - Create warehouse specifically used for ingestion
-- - Grants
-- REPLACE THE SESSION VARIABLE ACCORDING TO YOUR ENVIRONMENT
-- =========================
set processor_role = 'cl_bridge_process_rl';
set cl_bridge_ingestion_warehouse = 'cl_bridge_ingest_wh';
set staging_db = 'cl_bridge_stage_db';
set staging_db_schema = 'cl_bridge_stage_db.stage_db';
set node_db = 'cl_bridge_node_db';
set node_db_staging_schema = 'cl_bridge_node_db.stage_db';
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> ROLE CREATION >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
use role securityadmin;
create role if not exists identifier($processor_role)
comment = 'role used by cirruslink bridge to ingest and process mqtt/sparkplug data';
grant role identifier($processor_role)
to role sysadmin;
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> WAREHOUSE >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
use role sysadmin;
create warehouse if not exists identifier($cl_bridge_ingestion_warehouse) with
warehouse_type = standard
warehouse_size = xsmall
--max_cluster_count = 5
initially_suspended = true
comment = 'used by cirruslink bridge to ingest'
;
grant usage on warehouse identifier($cl_bridge_ingestion_warehouse)
to role identifier($processor_role);
grant operate on warehouse identifier($cl_bridge_ingestion_warehouse)
to role identifier($processor_role);
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS STAGE DB >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
grant usage on database identifier($staging_db)
to role identifier($processor_role);
grant usage on schema identifier($staging_db_schema)
to role identifier($processor_role);
grant select on all tables in schema identifier($staging_db_schema)
to role identifier($processor_role);
grant insert on all tables in schema identifier($staging_db_schema)
to role identifier($processor_role);
grant select on future tables in schema identifier($staging_db_schema)
to role identifier($processor_role);
grant insert on future tables in schema identifier($staging_db_schema)
to role identifier($processor_role);
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS NODE DB >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
grant usage on database identifier($node_db)
to role identifier($processor_role);
grant usage on schema identifier($node_db_staging_schema)
to role identifier($processor_role);
grant select on all tables in schema identifier($node_db_staging_schema)
to role identifier($processor_role);
grant insert on all tables in schema identifier($node_db_staging_schema)
to role identifier($processor_role);
grant select on all views in schema identifier($node_db_staging_schema)
to role identifier($processor_role);
grant usage on all functions in schema identifier($node_db_staging_schema)
to role identifier($processor_role);
grant usage on all procedures in schema identifier($node_db_staging_schema)
to role identifier($processor_role);
-- need for:
-- - creating edge node specific tables and views
grant create schema on database identifier($node_db)
to role identifier($processor_role);
|
- Expected Result: Statement executed successfully.
Script 11
| Code Block |
|---|
| language | sql |
|---|
| title | SQL Script 11 |
|---|
| collapse | true |
|---|
|
-- =========================
-- In this script, we are setting up roles specifically requiring help of
-- privlilleged roles like SYSADMIN, SECURITYADMIN, ACCOUNTADMIN. These are:
-- - Create a custom role
-- - Assign the custom role to create task and execute task
-- - Grants
-- REPLACE THE SESSION VARIABLE ACCORDING TO YOUR ENVIRONMENT
-- =========================
set reader_role = 'cl_bridge_reader_rl';
set reader_role_warehouse = 'compute_wh';
set staging_db = 'cl_bridge_stage_db';
set staging_db_schema = 'cl_bridge_stage_db.stage_db';
set node_db = 'cl_bridge_node_db';
set node_db_staging_schema = 'cl_bridge_node_db.stage_db';
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> ROLE CREATION >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
use role securityadmin;
create role if not exists identifier($reader_role)
comment = 'role used by user/process to query and operate on the views and tables managed by cirruslink bridge';
grant role identifier($reader_role)
to role sysadmin;
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS WAREHOUSE >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
use role accountadmin;
grant usage on warehouse identifier($reader_role_warehouse)
to role sysadmin with grant option;
grant modify on warehouse identifier($reader_role_warehouse)
to role sysadmin with grant option;
grant operate on warehouse identifier($reader_role_warehouse)
to role sysadmin with grant option;
use role sysadmin;
grant usage on warehouse identifier($reader_role_warehouse)
to role identifier($reader_role);
grant modify on warehouse identifier($reader_role_warehouse)
to role identifier($reader_role);
grant operate on warehouse identifier($reader_role_warehouse)
to role identifier($reader_role);
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS TASK EXECUTION >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
-- Creating and executing tasks require exculated privileges that can be done
-- only by the accountadmin. Hence we have to switch roles
-- use role accountadmin;
-- grant execute managed task on account to role identifier($reader_role);
-- grant execute task on account to role identifier($reader_role);
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS STAGE DB >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
grant usage on database identifier($staging_db)
to role identifier($reader_role);
grant usage on schema identifier($staging_db_schema)
to role identifier($reader_role);
grant select on all tables in schema identifier($staging_db_schema)
to role identifier($reader_role);
grant select on future tables in schema identifier($staging_db_schema)
to role identifier($reader_role);
-- >>>>>>>>>>>>>>>>>>>>>>>>>>> GRANTS NODE DB >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
grant usage on database identifier($node_db)
to role identifier($reader_role);
grant usage on schema identifier($node_db_staging_schema)
to role identifier($reader_role);
grant select on all tables in schema identifier($node_db_staging_schema)
to role identifier($reader_role);
grant select on all views in schema identifier($node_db_staging_schema)
to role identifier($reader_role);
grant usage on all functions in schema identifier($node_db_staging_schema)
to role identifier($reader_role);
grant usage on all procedures in schema identifier($node_db_staging_schema)
to role identifier($reader_role);
-- need for:
-- - new generated specific tables and views
use role securityadmin;
grant usage on future schemas in database identifier($node_db)
to role identifier($reader_role);
|
- Expected Result: Statement executed successfully.
After all of the scripts have successfully executed, create a new user in Snowflake. This user will be used by IoT Bridge for Snowflake to push data into Snowflake. In the Snowflake Web UI, go to Admin → Users & Roles and then click '+ User' in the upper right hand corner. Give it a username of your choice and a secure password as shown below. For this example we're calling the user IBSNOW_INGEST so we know this user is for ingest purposes. See below for an example and then click 'Create User'.
Image Removed
In addition, the user must have a specific role to be able to stream data into Snowflake. Click the newly created user to see the following.
Image Removed
In the bottom of the center 'Granted Roles' pane you will see this user has no roles. Click 'Grant Role' to set up a new role. Then, select the 'CL_BRIDGE_PROCESS_RL' role and click 'Grant' as shown below.
Image Removed
After this has been done successfully you will see the role now associated with the new user as shown below.
Image Removed
Now a key pair must be generated and uploaded to Snowflake. This will be used for authentication by the IoT Bridge for Snowflake application to push data to Snowflake via the Snowflake Streaming API. See this document for details on how to generate this and assign this to a user in your snowflake account: https://docs.snowflake.com/en/user-guide/key-pair-auth. Step 6 (Configuring the Snowflake Client to User Key Pair Authentication) in the linked tutorial can be skipped. This tutorial will cover configuring IoT Bridge for Snowflake with the generated key. Attach the public key to the user that we just created for Snowflake ingest purposes.
| Warning |
|---|
| The generated key MUST NOT be encrypted |
IoT Bridge Setup
With AWS IoT and Snowflake now properly provisioned and IBSNOW installed, IBSNOW must be configured. To configure it, you must be able to access it via SSH. Ensure you can access it via the Access Instructions here. Once you can access it, you must copy the three certificate files you captured when provisioning the AWS IoT Core thing. Again, these files are:
- UUID.certificate.pem.crt
- UUID.private.pem.key
- AmazonRootCA1.pem
On the target EC2 instance, the following directory exists to hold the certificates.
...
/opt/ibsnow/conf/certs
Now copy the three files to the /opt/ibsnow/conf/certs directory. To do this, first copy the files into the tmp folder of the EC2 instance using this command from your local:
...
scp -i /path/to/your.pem /path/to/your/filename ubuntu@[IP_ADDR]:/tmp/
Next, SSH into the instance:
...
ssh -i /path/to/your.pem ubuntu@[IP_ADDR]
Finally, move the files from the tmp folder into the destination folder by using this command:
...
sudo mv /tmp/filename /opt/ibsnow/conf/certs/
When done, it should look similar to what is shown below.
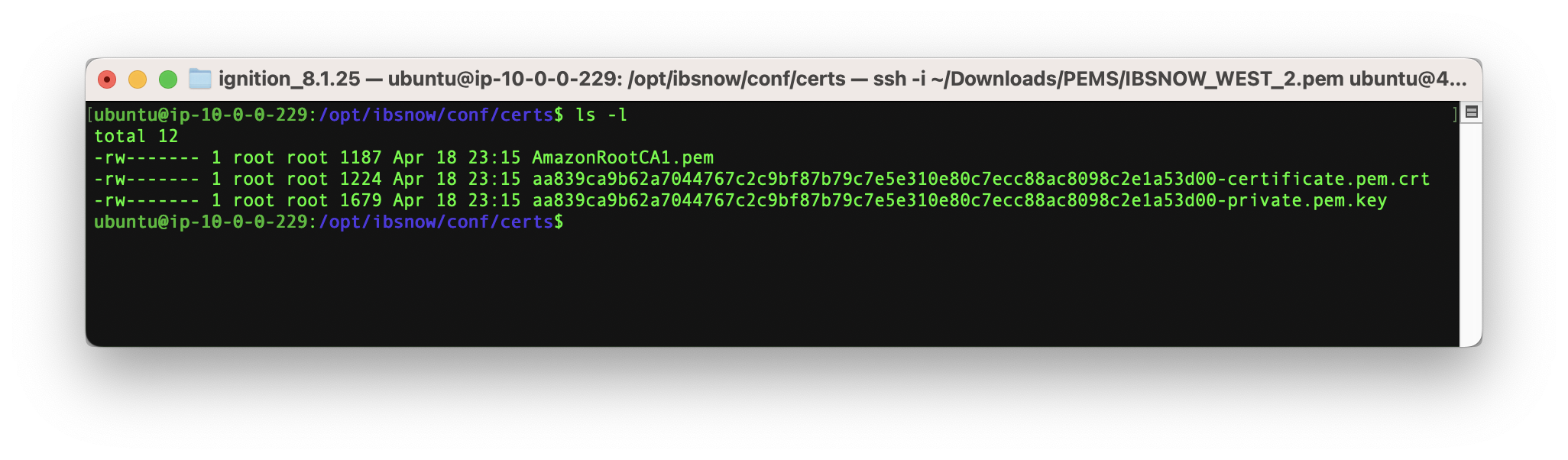 Image Removed
Image Removed
Note the files should be owned by root and not readable by other users. To set the ownership and permissions as shown above, run the following commands.
| Code Block |
|---|
|
sudo chown root:root /opt/ibsnow/conf/certs/*
sudo chmod 600 /opt/ibsnow/conf/certs/* |
Now, modify the file /opt/ibsnow/conf/ibsnow.properties file. Set the following:
- mqtt_server_url
- mqtt_server_name
- Give it a meaningful name such as 'AWS IoT Core Server'
- mqtt_ca_cert_chain_path
- The path to the AWS root CA certificate
- mqtt_client_cert_path
- The path to the AWS thing certificiate
- mqtt_client_private_key_path
- The path to the AWS thing private key
- primary_host_id
- Set it to a text string such as 'IamHost'
- snowflake_streaming_client_name
- Some text string such as 'MY_CLIENT'
- snowflake_streaming_table_name
- This must be 'SPARKPLUG_RAW' based on the scripts we previously used to provision Snowflake
- snowflake_notify_db_name
- This must be 'cl_bridge_node_db' based on the scripts we previously used to provision Snowflake
- snowflake_notify_schema_name
- This must be 'stage_db' based on the scripts we previously used to provision Snowflake
- snowflake_notify_warehouse_name
- This must be 'cl_bridge_ingest_wh' based on the scripts we previously used to provision Snowflake
When complete, it should look similar to what is shown below.
| Code Block |
|---|
| language | bash |
|---|
| title | ibsnow.properties |
|---|
|
# The IBSNOW instance friendly name. If ommitted, it will become 'IBSNOW-ec2-instance-id'
#ibsnow_instance_name =
# The Cloud region the IoT Bridge for Snowflake instance is in
#ibsnow_cloud_region = us-east-1
# The MQTT Server URL
mqtt_server_url = ssl://a3edk3kas32kf7n10-ats.iot.us-west-2.amazonaws.com:8883
# The MQTT Server name
mqtt_server_name = AWS IoT Core Server
# The MQTT username (if required by the MQTT Server)
#mqtt_username =
# The MQTT password (if required by the MQTT Server)
#mqtt_password =
# The MQTT keep-alive timeout in seconds
#mqtt_keepalive_timeout = 30
# The path to the TLS Certificate Authority certificate chain
mqtt_ca_cert_chain_path = /opt/ibsnow/conf/certs/AmazonRootCA1.pem
# The path to the TLS certificate
mqtt_client_cert_path = /opt/ibsnow/conf/certs/aa839ca9b62a7041aecffe79ddd9922286f12093444be8ac8098c2e1a53d00-certificate.pem.crt
# The path to the TLS private key
mqtt_client_private_key_path = /opt/ibsnow/conf/certs/aa839ca9b62a7041aecffe79ddd9922286f12093444be8ac8098c2e1a53d00-private.pem.key
# The TLS private key password
#mqtt_client_private_key_password =
# Whether or not to verify the hostname against the server certificate
#mqtt_verify_hostname = false
# The Sparkplug sequence reordering timeout in milliseconds
sequence_reordering_timeout = 5000
# Whether or not to block auto-rebirth requests
#block_auto_rebirth = false
# The primary host ID if this is the acting primary host
primary_host_id = IamHost
# The MQTT Client ID - It is recommend to not set this unless there is a specific reason to do so. If this is not set a random client ID will be automatically generated
#client_id =
# Snowflake streaming connection properties - A custom client name for the connection (e.g. MyClient)
snowflake_streaming_client_name = MY_CLIENT
# Snowflake streaming connection properties - A custom channel name for the connection (e.g. MyChannel)
# If this is left blank/empty, Channel names of the Sparkplug Group ID will be used instead of a single channel
#snowflake_streaming_channel_name =
# Snowflake streaming connection properties - The Table name associated with the Database and Schema already provisioned in the Snowflake account (e.g. MyTable)
snowflake_streaming_table_name = SPARKPLUG_RAW
# Snowflake notify connection properties - The Database name associated with the connection that is already provisioned in the Snowflake account (e.g. MyDb)
snowflake_notify_db_name = cl_bridge_node_db
# Snowflake notify connection properties - The Schema name associated with the Database already provisioned in the Snowflake account (e.g. PUBLIC)
snowflake_notify_schema_name = stage_db
# Snowflake notify connection properties - The Warehouse name associated with the notifications already provisioned in the Snowflake account (e.g. PUBLIC)
snowflake_notify_warehouse_name = cl_bridge_ingest_wh
# Whether or not to create and update IBSNOW infomational tracking metrics
# ibsnow_metrics_enabled = true
# The Sparkplug Group ID to use for IBSNOW asset names
ibsnow_metrics_sparkplug_group_id = IBSNOW Metrics
# Whether or not to send notification tasks to Snowflake based on incoming Sparkplug events
snowflake_notify_task_enabled = true
# The number of milliseconds to delay after receiving an NBIRTH before notifying Snowflake over the event (requires snowflake_notify_task_enabled is true)
snowflake_notify_nbirth_task_delay = 10000
# The number of milliseconds to delay after receiving a DBIRTH or DATA message before notifying Snowflake over the event (requires snowflake_notify_task_enabled is true)
snowflake_notify_data_task_delay = 5000 |
Now, modify the file /opt/ibsnow/conf/snowflake_streaming_profile.json file. Set the following:
- user
- This must be 'IBSNOW_INGEST' based on the user we provisioned in Snowflake earlier in this tutorial
- url
- Replace 'ACCOUNT_ID' with your Snowflake account id. Leave the other parts of the URL the same.
- account
- Replace 'ACCOUNT_ID' with your Snowflake account id
- private_key
- Replace with the text string that is the private key you generated earlier in this tutorial
- host
- Replace 'ACCOUNT_ID' with your Snowflake account id. Leave the other parts of the hostname the same.
- schema
- Set this to 'stage_db' based on the scripts we previously used to provision Snowflake
- database
- Set this to 'cl_bridge_stage_db' based on the scripts we previously used to provision Snowflake
- connect_string
- Replace 'ACCOUNT_ID' with your Snowflake account id. Leave the other parts of the connection string the same.
- warehouse
- Set this to 'cl_bridge_ingest_wh' based on the scripts we previously used to provision Snowflake
- role
- Set this to 'cl_bridge_process_rl' based on the scripts we previously used to provision Snowflake
When complete, it should look similar to what is shown below.
| Code Block |
|---|
| language | bash |
|---|
| title | snowflake_streaming_profile.json |
|---|
|
{
"user": "IBSNOW_INGEST",
"url": "https://RBC48284.snowflakecomputing.com:443",
"account": "RBC48284",
"private_key": "MIIEwAIBADANBgkqhkiG9w0BAQEFAASCBKowggSmAgEAAoIBAQDN6NOoaoVVZSz/AIUohNn9oJThwDZg2/qASsIRYFjy0pSNKh+XsG6yp4kteII900lEgt5koroU+8oQrX7vnTI/69mvc5o+xJBfGogd+qcdw9tEEUZHEfBxBtlpZvfMY/HHyrilQBvWVrFqB3hYt9n15lE/wVi1LDII378yh2p+QcwEaKhKD1aWBYUlpOoA0d2214/UQiU6ytI18jJNPN3yQv9Jx3+/DRldlYh5fLIQ0AWbBqRnQoyLvLaYRIgynxDhrQpVtw8QN2M/XQErT3OxZzti7CKeI9M4xLchO3VZozsde5kcQwCIcop05PX6dtdSsqheQBRrhytf1K9GnfGdAgMBAAECggEBAKO8auLXoaMgS0GTlk98JSRL11gU0qj/BBmUWPIcXV7qGPqP7oNe5wfltW2VEGw9YVu7fUElLTeWaT4N2IyNwfGWiIm+MX+MKwmVPXwpX06J+ggMfIfzOfGG8sef+5hqOU8YYu/1JK2yTm3z9r0FpaqmNSGvi+y1ciwgUBfMGuC93pySQCHuNXkWw2njxvaltpOSm9H08aQtXsA+1JL31kP4WZAexk2EqzRzEka8hrGYfNIs9qQimKI9XznNoqmlSN6ZIO+A5e+kSUg0viyY/cZLwVj5FYV/wKN49WDDkB3dthCbx1Z1VuIw7rub9VU609eoTXDxEgMMBEDqbE5BXkECgYEA/ZsySGO2QouCihpPp0VtNrNh7PhA/OLch5zZt2iJBMhbjPn4SAyrzgi6lQc7b4oZOznOK5jOL4NQijt7SGz8rfrwfTd5Rl84lHlN7Cu3V0lBC8IN6JcXWBuTedmF7ShlL5ATbpXTsgaaqPm3H8VCS4fkoQ54bDZnCjI5/GtI5OkCgYEAz9pgvqXCXyJQxj5bM0uihZV3lZzvwpqlEuT0GvT9XqHM+LNKtf2kQ958qRq5Nh381oeRLyVbZTFrr0eNCCEA5YesbmxE7d/5vlWszfW5e70TUJEWbk0rrGNmqVUlAfEZKfK6ms87W3peHqqMyXqnmMwwecMl2c013XZaLKYxRpUCgYEAnWgHdKDXDkSTGG6uQ882sz3xqOiJRaz1XgK/qzPp35sQH9dDAE1FEZOfY0Ji5J8dfAIr8ilcyGbDxZiXs2NaDg5z1/RnhIMzlgwYjl6v5DBmfArNITEuXxR2m6mkk4eADl5pgTjjdVreAcVEoSaJOGI3SLO3kMrPd6enEAHy84kCgYEAsL2BjDtI1zpHsvqs9CY5URuybt7epPx4p2NWCmIN3Fz6/PL/8VZ3SlqyZ9zYZqMDLqxiENPULmzio03VJ3dg2swOHGsmBZtxMp6JbSyoBwbUmKp2h15JZ7GyRwSmjksj2Z6TfDYAxB1+UNc3Fc+dGXlvMup0kgpD5kfQD61Vsy0CgYEAn9QCQG+lcPG5GXXu3EAeVzqgy+gOXpyd4ys0fdssFF93AM+/Dd9F31sSSfdasEQ8+jFKjunEeQAOiecVQA4Vu9GGQAykrK/m8nD0zf02L1QpADTBA8TymkpD1yFEMo+T5DrZ24SRCl/zREb0hLn//ZOA=",
"port": 443,
"host": "RBC48284.snowflakecomputing.com",
"schema": "stage_db",
"scheme": "https",
"database": "cl_bridge_stage_db",
"connect_string": "jdbc:snowflake://RBC48284.snowflakecomputing.com:443",
"ssl": "on",
"warehouse": "cl_bridge_ingest_wh",
"role": "cl_bridge_process_rl"
} |
Now the service can be restarted to pick up the new configuration. Do so by running the following command.
sudo /etc/init.d/ibsnow restart
|
At this point, IBSNOW should connect to AWS IoT Core and be ready to receive MQTT Sparkplug messages. Verify by running the following command.
...
tail -f /opt/ibsnow/log/wrapper.log
After doing so, you should see something similar to what is shown below. Note the last line is 'MQTT Client connected to ...'. That denotes we have successfully configured IBSNOW and properly provisioned AWS IoT Core.
| Code Block |
|---|
|
INFO|199857/0||23-04-21 15:29:52|15:29:52.401 [Thread-2] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-79456ef7-8c90-45: Creating the MQTT Client to ssl://a3een7lsei6n10-ats.iot.us-west-2.amazonaws.com:8883 on thread Thread-2
INFO|199857/0||23-04-21 15:29:55|15:29:55.836 [MQTT Call: IBSNOW-79456ef7-8c90-45] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-79456ef7-8c90-45: connect with retry succeeded
INFO|199857/0||23-04-21 15:29:55|15:29:55.839 [MQTT Call: IBSNOW-79456ef7-8c90-45] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-79456ef78bc00095-8c909265-45: Connected41: Creating the MQTT Client to ssl://a3een7lsei6n10-ats54.iot.us-west-2.amazonaws.com:8883236.16.39:8883 on thread Thread-2
INFO|1998577263/0||23-0406-2129 1520:2919:5633|1520:2919:5633.046275 [Thread-2MQTT Call: IBSNOW-8bc00095-9265-41] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-8bc00095- IBSNOW-79456ef7-8c90-45: MQTT Client connected to ssl://a3een7lsei6n10-ats.iot.us-west-2.amazonaws.com:8883 on thread Thread-2 |
Edge Setup with Ignition and MQTT Transmission
At this point IoT Bridge is configured and ready to receive data. To get data flowing into IBSNOW we'll set up Inductive Automation's Ignition platform along with the MQTT Transmission module from Cirrus Link. Begin by downloading Ignition here.
https://inductiveautomation.com/downloads
Installation of Ignition is very straightforward and fast. There is a guide to do so here.
https://docs.inductiveautomation.com/display/DOC80/Installing+and+Upgrading+Ignition
With Ignition installed, MQTT Transmission must be installed as well as a plugin to Ignition. Get MQTT Transmission for your version of Ignition here.
https://inductiveautomation.com/downloads/third-party-modules
Now use the procedure below to install the MQTT Transmission module.
https://docs.inductiveautomation.com/display/DOC80/Installing+or+Upgrading+a+Module
With Ignition and MQTT Transmission installed, we can configure the MQTT Transmission module to connect to AWS IoT Core using the same certificates that we provisioned earlier. Begin by clicking 'Get Desginer' in the upper right hand corner of the Ignition Gateway Web UI as shown below.
 Image Removed
Image Removed
Now launch the Ignition Designer using the Designer Launcher as shown below.
 Image Removed
Image Removed
Once it is launched, you should see something similar to what is shown below. Note the Tag Browser has been expanded and the automatically created example tags have been highlighted.
 Image Removed
Image Removed
Begin by deleting these two tags (Example Tag and MQTT Quickstart). Then click the 'UDT Definitions' tab as shown below. We will use this view to create a very simple UDT definition.
 Image Removed
Image Removed
Now, click the '+' icon in the upper left corner of the tag browser as shown below and select 'New Data Type'
 Image Removed
Image Removed
This will open the following dialog box.
 Image Removed
Image Removed
Change the name of the tag to Motor as shown below. Also, note the highlighted 'new member tag' icon in the middle of the dialog. We'll use this to create some member tags.
 Image Removed
Image Removed
Now use the 'new member tag' button to create a new 'memory tag' as shown below.
 Image Removed
Image Removed
Then, set the following parameters for the new memory tag.
- Name
- Date Type
- Engineering Units
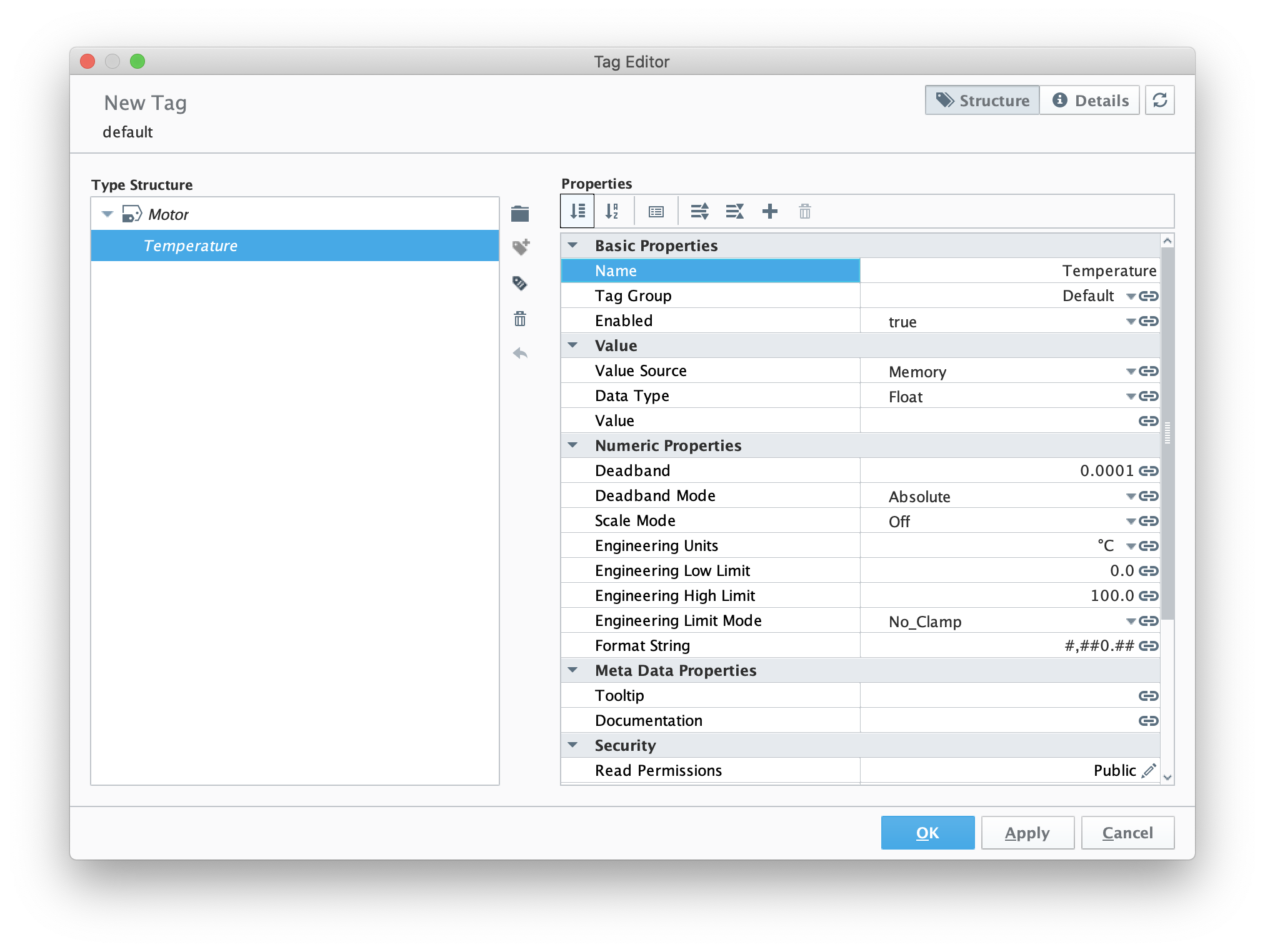 Image Removed
Image Removed
Now create two additional member tags with the following configuration.
- Amps
- Memory tag
- Data Type = Integer
- RPMs
- Memory tag
- Data Type = Integer
When complete, the UDT definition should look as follows.
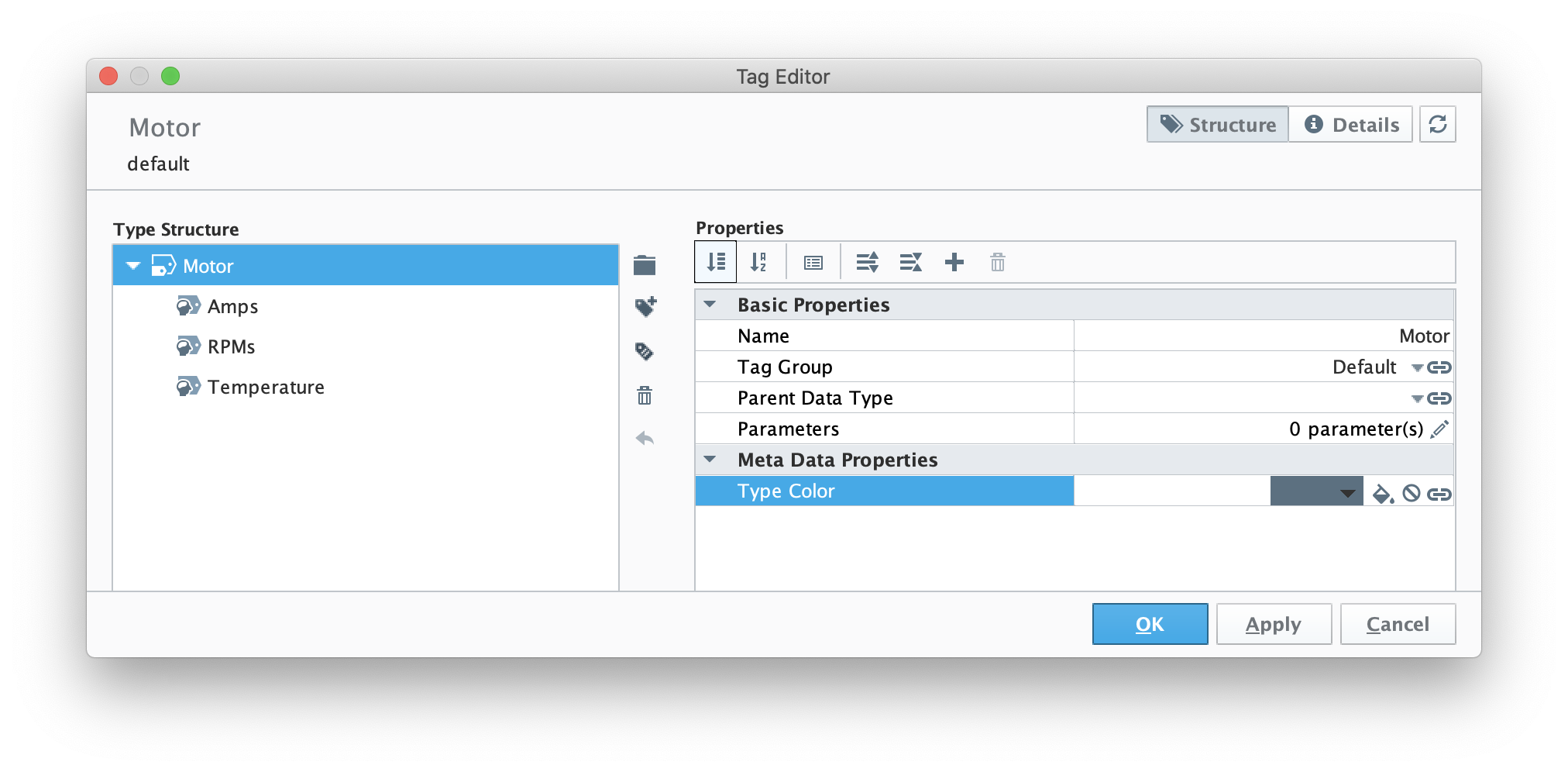 Image Removed
Image Removed
Now switch back to the 'Tags' tab of the Tag Browser. Right click on the 'PLC 1' folder and select 'New Tag → Data Type Instance → Motor' as shown below.
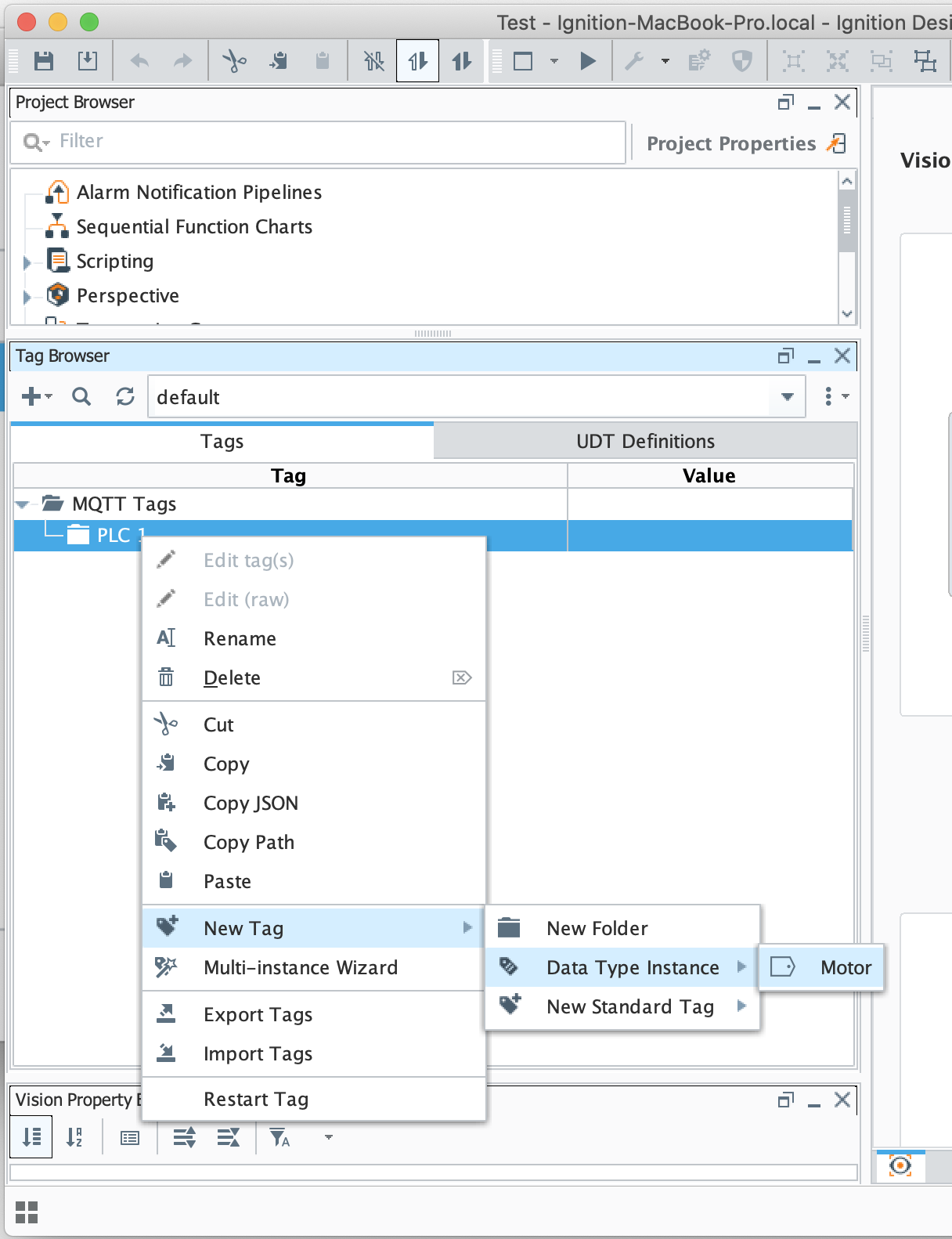 Image Removed
Image Removed
Now set the name to 'My Motor' as shown below and click OK.
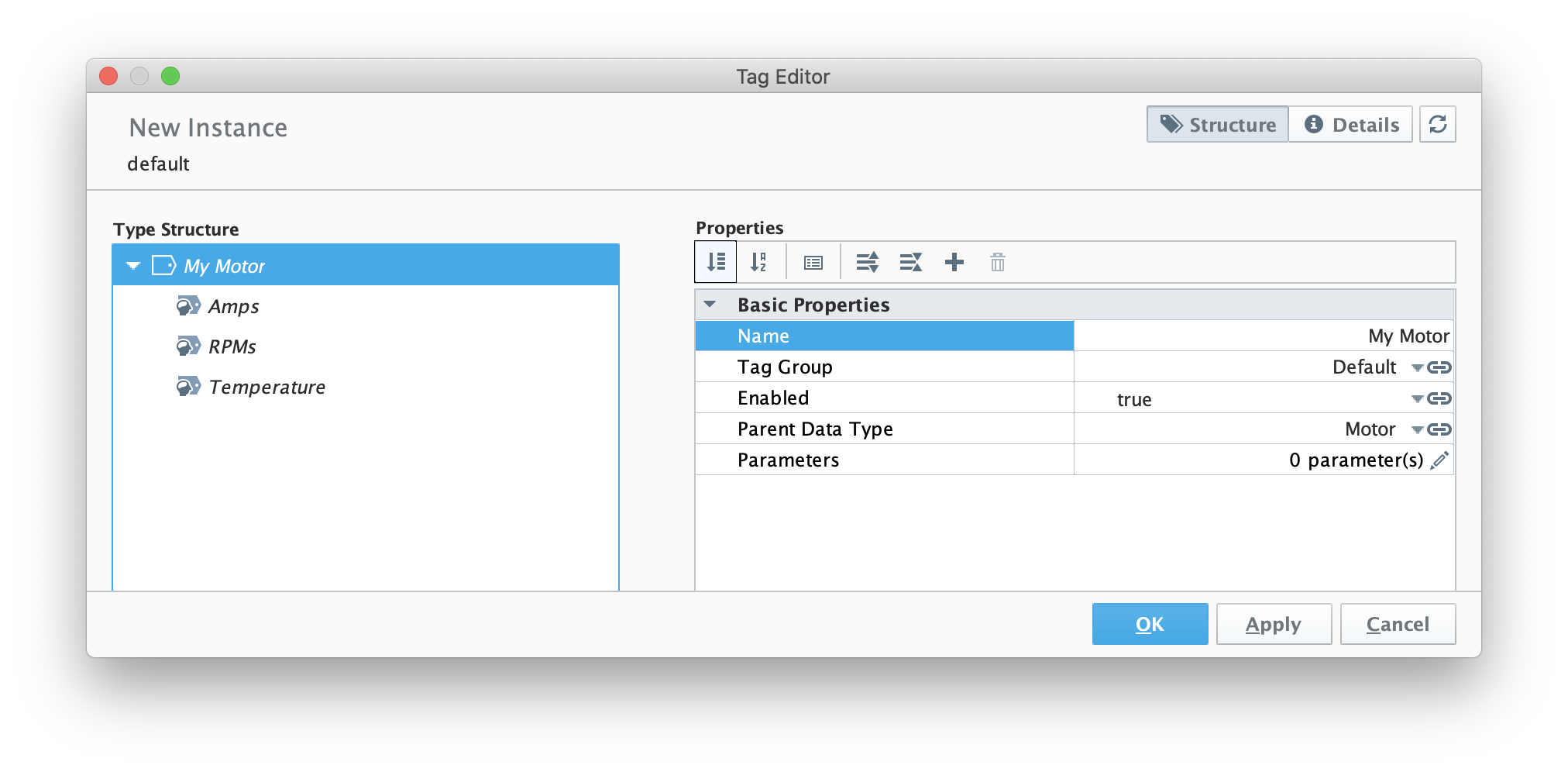 Image Removed
Image Removed
Now, set some values under the instance as shown below.
...
9265-41: connect with retry succeeded
INFO|7263/0||23-06-29 20:19:33|20:19:33.280 [MQTT Call: IBSNOW-8bc00095-9265-41] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-8bc00095-9265-41: Connected to ssl://54.236.16.39:8883
INFO|7263/0||23-06-29 20:19:33|20:19:33.294 [MQTT Call: IBSNOW-8bc00095-9265-41] INFO o.eclipse.tahu.host.TahuHostCallback - This is a offline STATE message from IamHost - correcting with new online STATE message
FINEST|7263/0||23-06-29 20:19:33|20:19:33.297 [MQTT Call: IBSNOW-8bc00095-9265-41] INFO o.eclipse.tahu.host.TahuHostCallback - This is a offline STATE message from IamHost - correcting with new online STATE message
FINEST|7263/0||23-06-29 20:19:33|20:19:33.957 [Thread-2] INFO org.eclipse.tahu.mqtt.TahuClient - IBSNOW-8bc00095-9265-41: MQTT Client connected to ssl://54.236.16.39:8883 on thread Thread-2 |
Edge Setup with Ignition and MQTT Transmission
Install Ignition and MQTT Transmission module
At this point IoT Bridge is configured and ready to receive data. To get data flowing into IBSNOW we'll set up Inductive Automation's Ignition platform along with the MQTT Transmission module from Cirrus Link.
Installation of Ignition is very straightforward following the instructions in the Installing and Upgrading Ignition guide.
With Ignition installed, the Cirrus Link MQTT Transmission module must be installed as a plugin to Ignition. Follow the instructions in our Module Installation guide
Import UDTs and tags
Launch the Ignition Designer to connect to your Ignition instance.
Once it is launched, navigate to the 'default' tag provider in the Tag Browser, expand the tag tree to see the automatically created tags as shown below and delete tags Example Tag and MQTT Quickstart.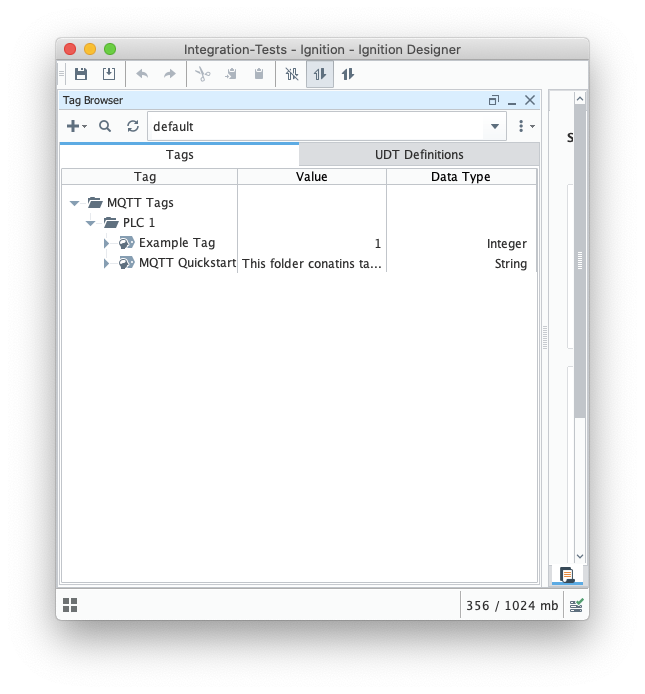 Image Added
Image Added
from the Designer import these tags IBSNOW_Quickstart_tags.json to MQTT Tags > PLC 1 create a UDT Definition and instance.
You can view the imported UDT Definition and instance in the tag browser:
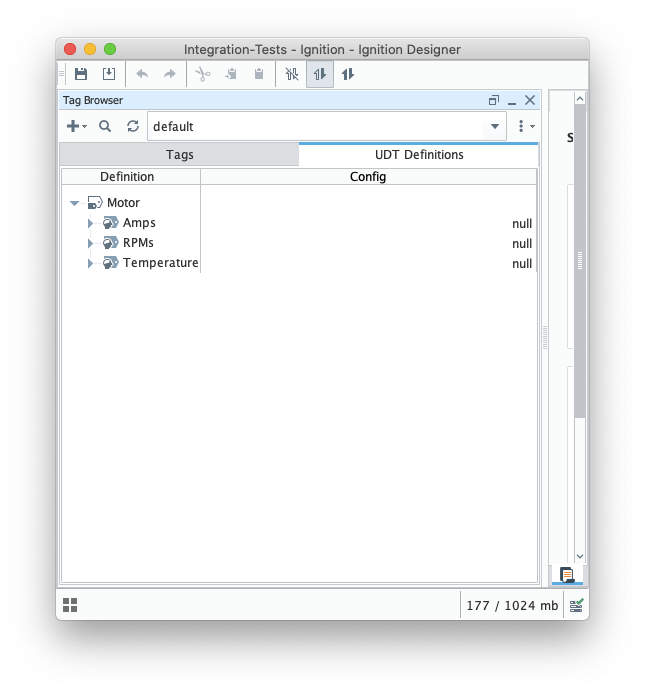 Image Added
Image Added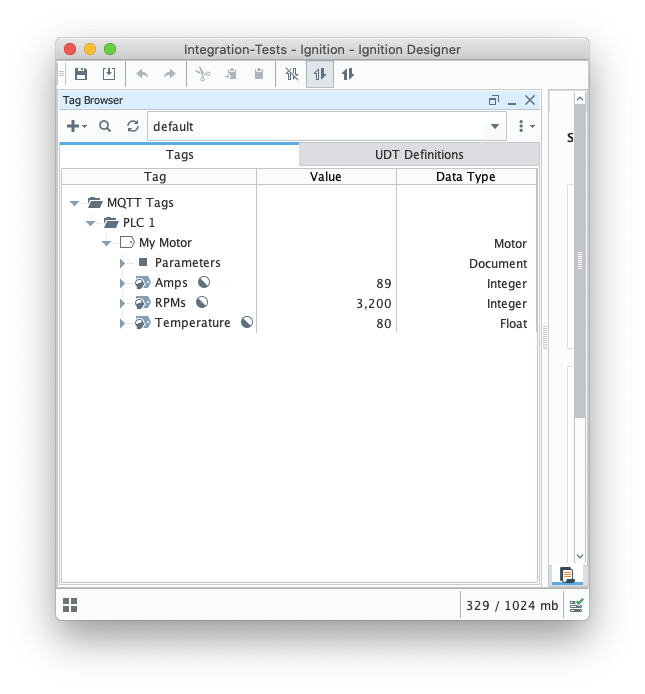 Image Added
Image Added
At this point, our tags are configured. A UDT definition will map to a model in Snowflake and UDT instances in Ignition will map to Snowflake.
But, before this will happen we need to point MQTT Transmission to AWS IoT Corethe Chariot MQTT Server. To do so, browse back to the Ignition Gateway Web UI and select MQTT Transmission → Settings from the left navigation panel as shown below. Image Removed
Image Removed
Now select the 'Transmitters' tab as shown below. Image Added
Image Added
 Image Removed
Image Removed
Now click the 'edit' button to the right of the 'Example Transmitter'. Scroll down to the 'Convert UDTs' option and uncheck it as shown below. This will also un-grey the 'Publish UDT Defintions' option. Leave it selected as shown below.
 Image Removed
Image Removed
Then select the 'Servers' tab and 'Certificates' tab as shown below.
 Image Removed
Image Removed
Now upload the three certificate files that were acquired during the AWS IoT thing provisioning. Upload all three to the MQTT Transmission configuration. When done, you should see something similar to what is shown below.
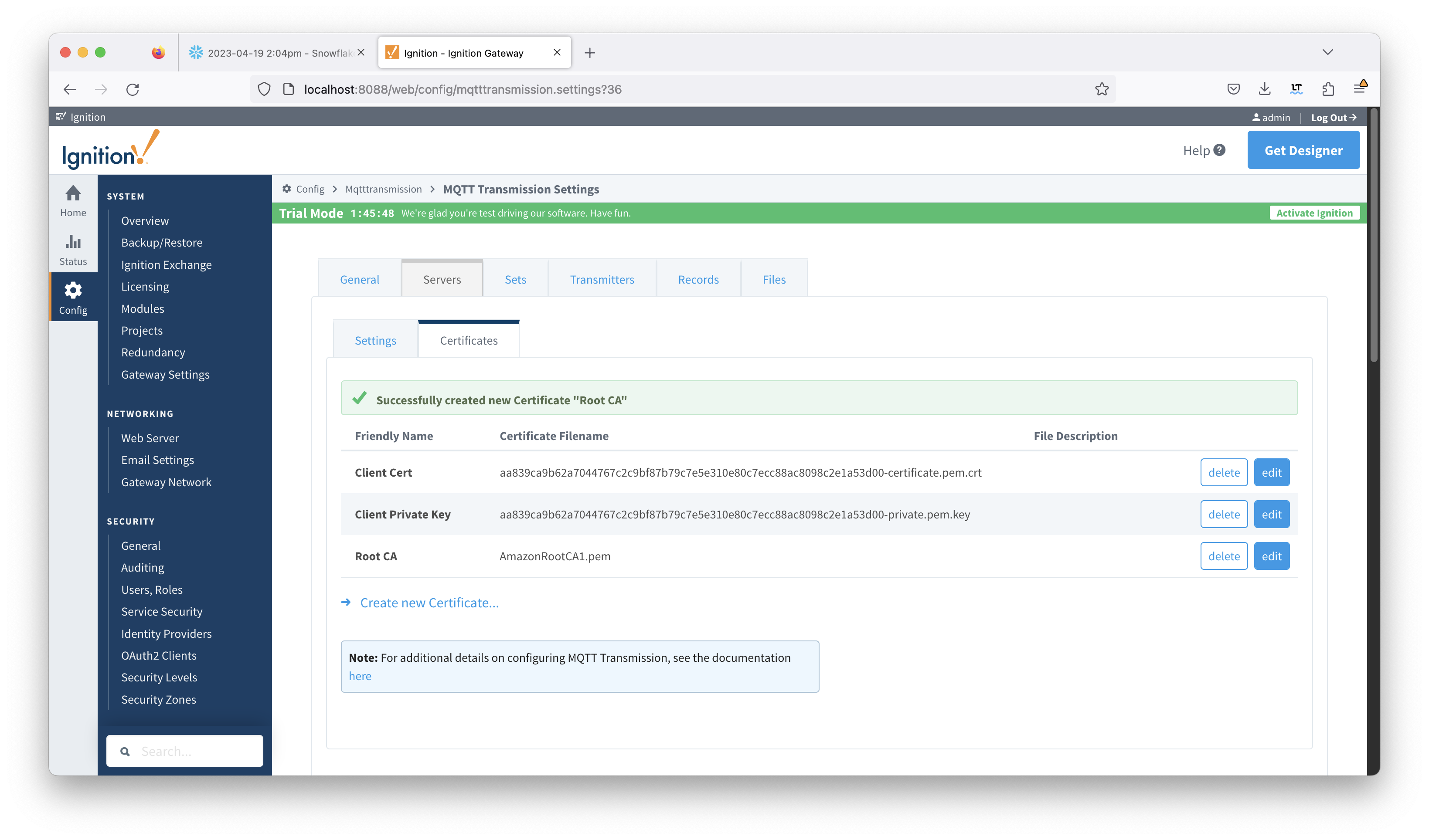 Image RemovedDefinitions' option. Leave it selected as shown below.
Image RemovedDefinitions' option. Leave it selected as shown below.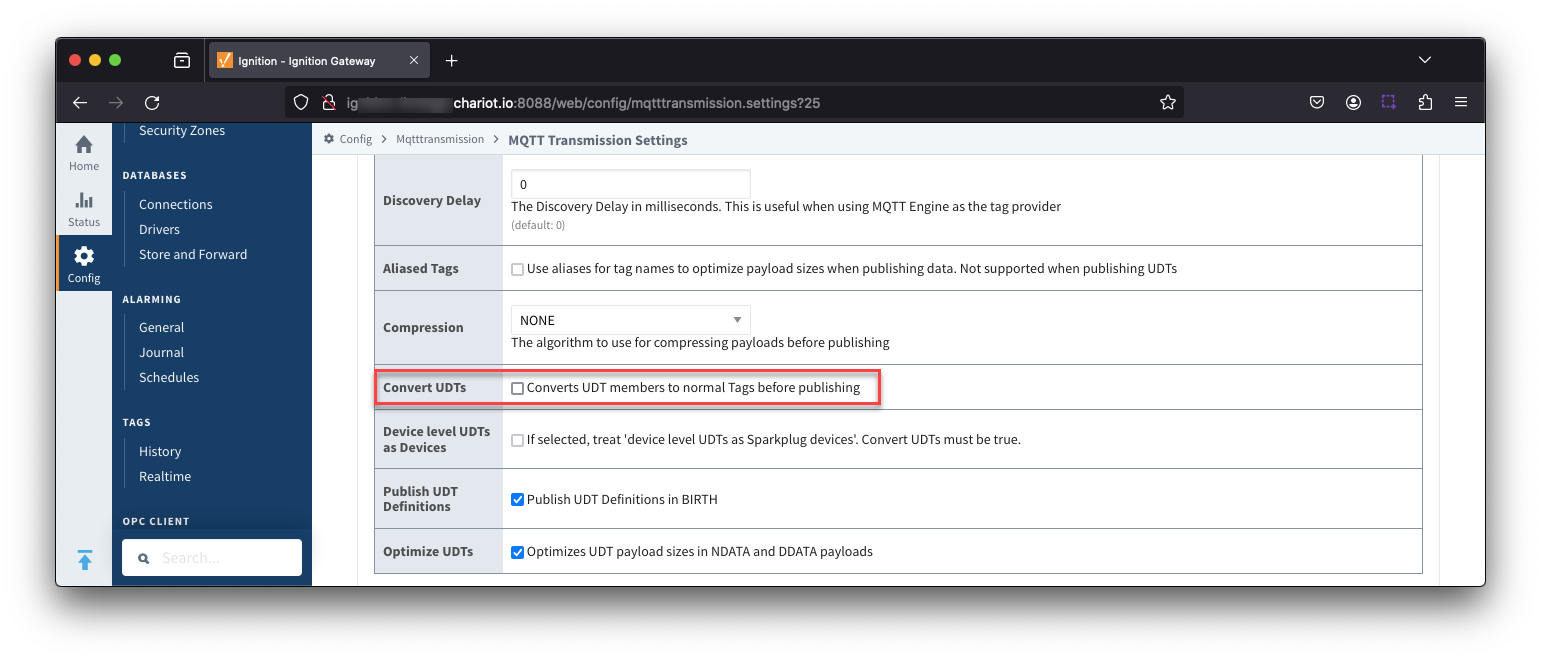 Image Added
Image Added
Now switch to the 'Servers' and 'Settings' tab. Delete the existing 'Chariot SCADA' pre-seeded MQTT Server Definition. Then create a new one with the following configuration.
- Name
- AWS IoTChariot MQTT Server
- URL
- CA Certificate File
- The AWS Root CA certificate
- Client Certificate File
- The AWS client certificate for your provisioned 'thing'
- Username
- Your username for the Chariot MQTT Server connection
- If using Chariot MQTT Server, the default username is 'admin'
- Password
- Your password for the Chariot MQTT Server connection
- If using Chariot MQTT Server, the default password is 'changeme
Client Private Key File- The AWS client private key for your provisioned 'thing'
When complete, you should see something similar to the following. However, the 'Connected' state should show '1 of 1' if everything was configured properly.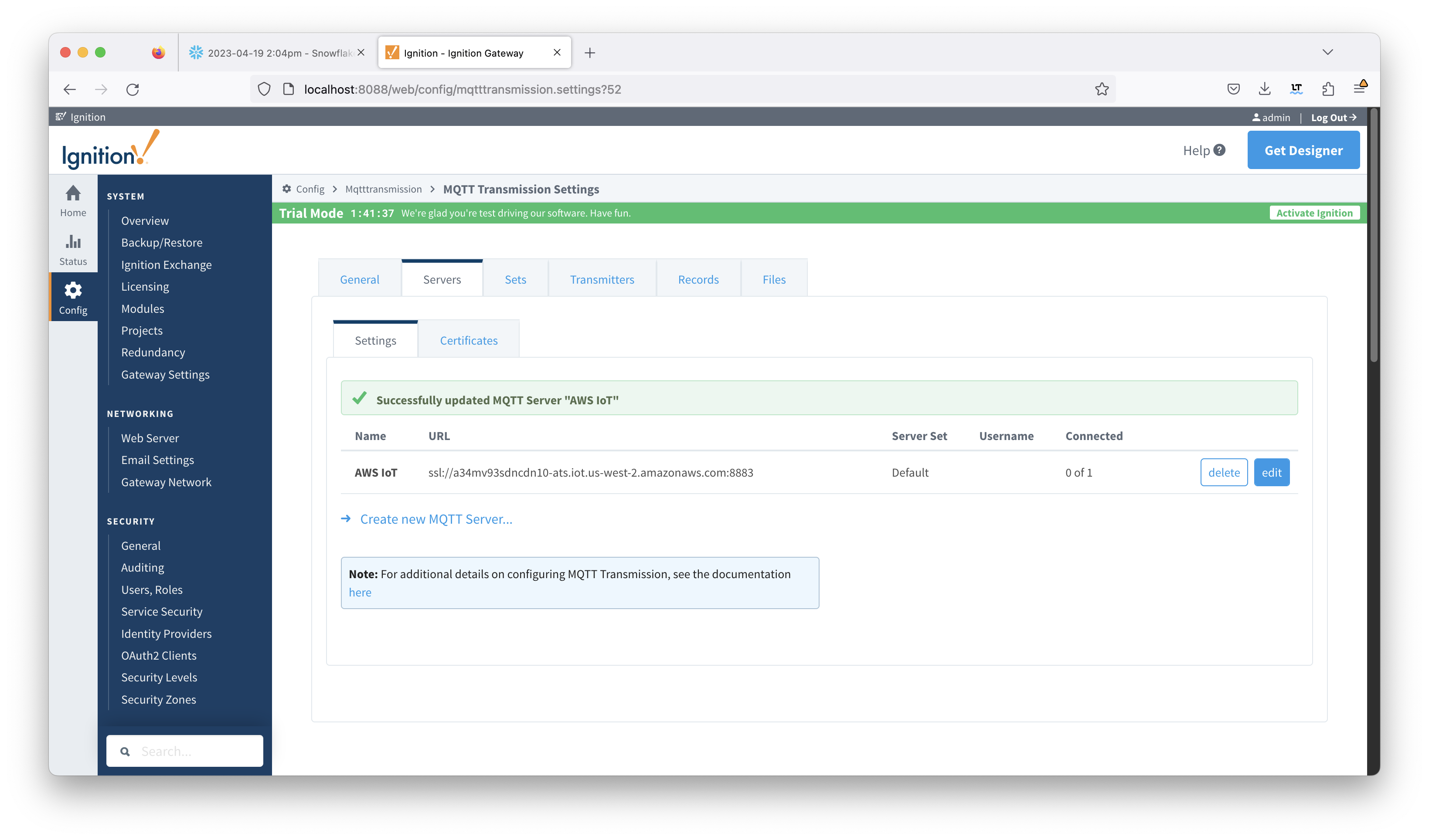 Image Removed
Image Removed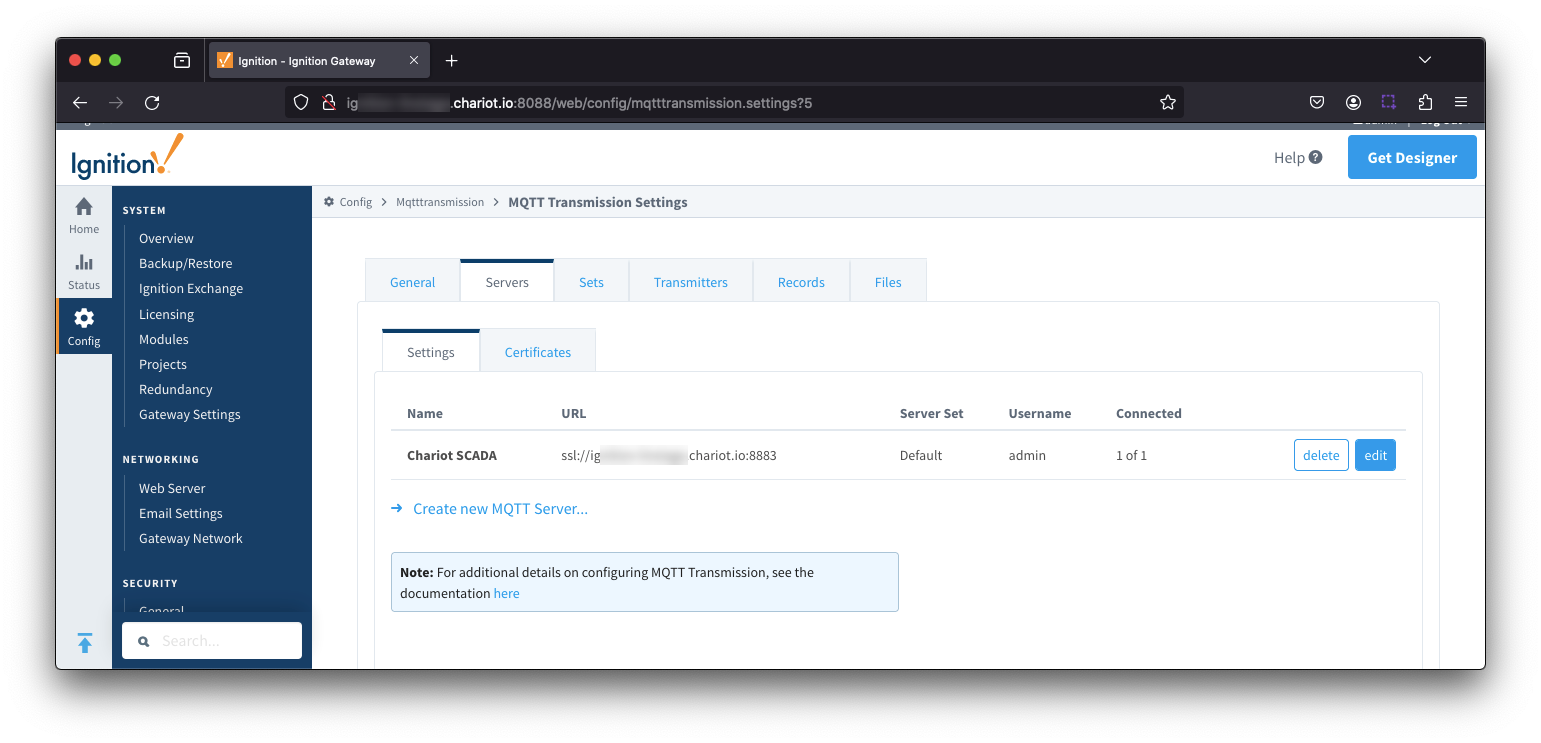 Image Added
Image Added
At this point, data should be flowing into Snowflake.
By tailing the log in IBSNOW you should see something similar to what is shown below . This which shows IBSNOW receiving the messages published from Ignition/MQTT Transmission.
When IBSNOW receives the Sparkplug MQTT messages, it creates and updates asset models and assets in Snowflake. The log below is also a useful debugging tool if things don't appear to work as they should.
...